学习资料
“What I cannot create, I do not understand” - Richard Feynman
PyTorch Tutorial by Python Engineer
☆☆☆☆☆
讲解深度学习内在过程
Neural Network Programming - Deep Learning with PyTorch
☆☆☆☆☆
超棒的教学视频,把底层原理到实现的具体过程讲得通俗易懂
一个韩国小哥哥写的非常精炼的Pytorch教程,大部分模型用30行代码完成
PyTorch Zero To All
一个韩国小哥哥的教程,教学视频讲得很形象
比较详细的Pytorch中文教程,从官方的60分钟入门简介到神经网络再到应用均进行了介绍
深度学习课程 by Yann LeCun 和 Alfredo Canziani
神经网络内部推导
其他资料:
PyTorch 中文手册
新手如何入门pytorch?
笔记
conda管理环境
conda可以创建不同python版本的虚拟环境
创建虚拟环境:如环境名为dl,则
conda create -n dl python=3.6激活虚拟环境:
conda activate dl退出虚拟环境:
conda deactivate dl其他:
- 删除一个已有环境:
conda remove --name dl --all - 列出已有的环境:
conda info -e - 安装package:
conda install -n dl numpy, 如果不用-n指定环境名称,则默认安装在当前激活环境中
- 删除一个已有环境:
pytorch中安装tensorboard及tensorboard使用示例
- HOW TO USE TENSORBOARD WITH PYTORCH
- 进入创建的环境,如
conda activate dl。在该环境中安装:conda install -c conda-forge tensorboardconda install -c conda-forge protobuf
- 在自己的.py文件中加入
from torch.utils.tensorboard import SummaryWriter,则项目中会建立一个runs文件夹,该文件夹中保存该项目中tensorboard相关信息 - cd到当前项目路径,运行
tensorboard --logdir=runs,将localhost粘贴到浏览器中
- 进入创建的环境,如
- HOW TO USE TENSORBOARD WITH PYTORCH
pytorch维度解释
The way to understand the “axis” of numpy sum is that it collapses the specified axis.
import torch
T1 = torch.tensor([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]
])
T2 = torch.tensor([[10, 20, 30],
[40, 50, 60],
[70, 80, 90]])
print(torch.stack((T1,T2),dim=0).shape)
print(torch.stack((T1,T2),dim=0))
# torch.Size([2, 3, 3])
# tensor([[[ 1, 2, 3],
# [ 4, 5, 6],
# [ 7, 8, 9]],
# [[10, 20, 30],
# [40, 50, 60],
# [70, 80, 90]]])
print(torch.stack((T1,T2),dim=1).shape)
print(torch.stack((T1,T2),dim=1))
# torch.Size([3, 2, 3])
# tensor([[[ 1, 2, 3],
# [10, 20, 30]],
#
# [[ 4, 5, 6],
# [40, 50, 60]],
#
# [[ 7, 8, 9],
# [70, 80, 90]]])
print(torch.stack((T1,T2),dim=2).shape)
print(torch.stack((T1,T2),dim=2))
# torch.Size([3, 3, 2])
# tensor([[[ 1, 10],
# [ 2, 20],
# [ 3, 30]],
#
# [[ 4, 40],
# [ 5, 50],
# [ 6, 60]],
#
# [[ 7, 70],
# [ 8, 80],
# [ 9, 90]]])
论文
- 应用于语义分割问题的深度学习技术综述
- 包含多种经典网络的总结
- 包含常用数据集(rgb及深度数据集)的概述
hook
Misc
- 以书为类比,解释Batch Normalization (BN)
- scikit-learn 中 fit_transform() 和 transform() 的原因
- 训练数据用fit_transform
- 测试数据用transform,Using the transform method we can use the same mean and variance as it is calculated from our training data to transform our test data. Thus, the parameters learned by our model using the training data will help us to transform our test data.
__init__()与__getitem__()及__len__()- Dataset类中的getitem和 len方法
- torch.utils.data.Dataset是PyTorch中用来表示数据集的抽象类,Dataset是一个包装类,用来将数据包装为Dataset类,然后传入DataLoader中从而使DataLoader类更加快捷的对数据进行操作。当处理自定义的数据集的时候必须继承Dataset,然后重写 len()和getitem()函数
- Dataset类中的getitem和 len方法
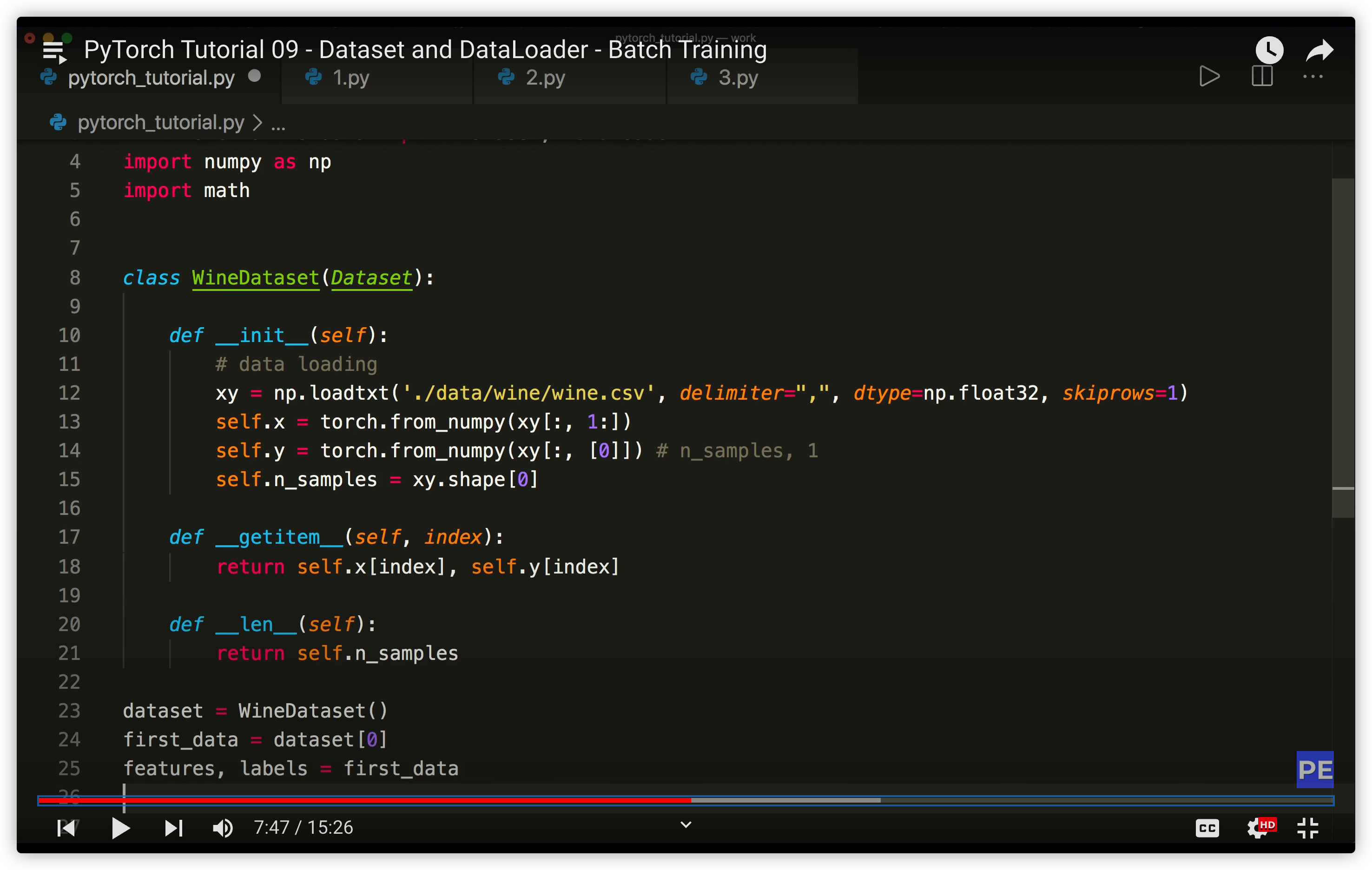
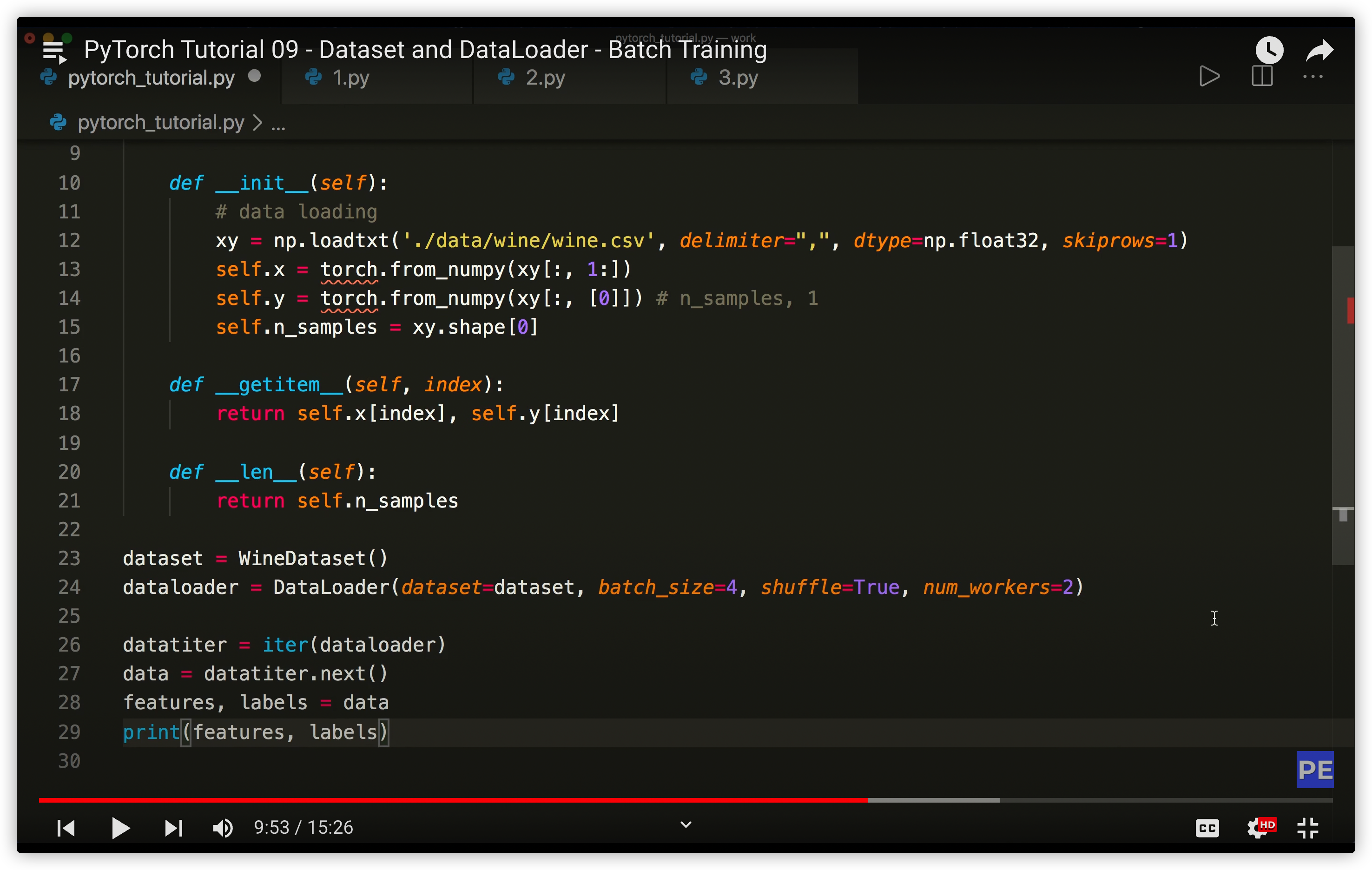
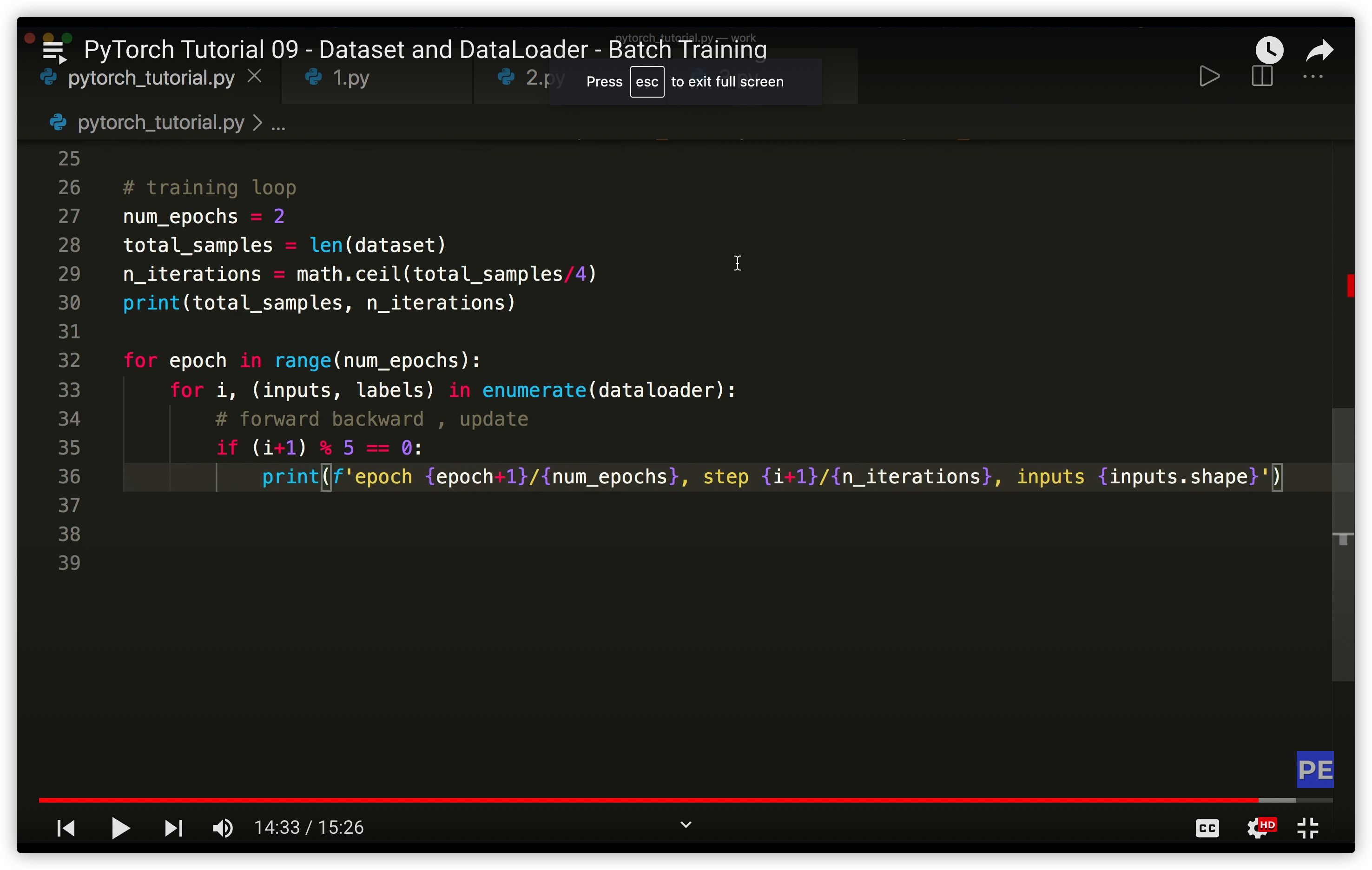
-
- 如果卷积的输出输入都只是一个平面,那么1x1卷积核并没有什么意义,它是完全不考虑像素与周边其他像素关系。 但卷积的输出输入是长方体,所以1x1卷积实际上是对每个像素点,在不同的channels上进行线性组合(信息整合),且保留了图片的原有平面结构,调控depth,从而完成升维或降维的功能
数据维度计算公式:Convolutional Neural Networks cheatsheet

Why 2D batch normalisation is used in features and 1D in classifiers?
- There is no mathematical difference between them, except the dimension of input data.
nn.BatchNorm2d only accepts 4D inputs while nn.BatchNorm1d accepts 2D or 3D inputs. And because of that, in features which has been constructed of nn.Conv2d layers, inputs are [batch, ch, h, w] (4D) we need BatchNorm2d and in classifier we have Linear layers which accept [batch, length] or [batch, channel, length] (2D/3D) so we need BatchNorm1d.
- torchsummary用于描述网络; thop用于统计模型的floating point operations per second (FLOPS)和参数量
import torch
import torch.nn as nn
import torchsummary
import thop
class BaseNet(nn.Module):
def __init__(self, in_ch, out_ch, group=1):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=in_ch, out_channels=out_ch,
groups=group, kernel_size=3, stride=1,
padding=1, bias=False)
def forward(self, x):
x = self.conv1(x)
return x
model = BaseNet(6, 3)
input_tensor = torch.rand(1,6,64,64)
input_size = tuple(input_tensor.shape[1:])
torchsummary.summary(model, input_size=input_size, batch_size=1)
print("thop:")
flops, params = thop.profile(model=model, inputs=(input_tensor,))
print(flops, params)
输出:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [1, 3, 64, 64] 162
================================================================
Total params: 162
Trainable params: 162
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.09
Forward/backward pass size (MB): 0.09
Params size (MB): 0.00
Estimated Total Size (MB): 0.19
----------------------------------------------------------------
thop:
[INFO] Register count_convNd() for <class 'torch.nn.modules.conv.Conv2d'>.
[WARN] Cannot find rule for <class '__main__.BaseNet'>. Treat it as zero Macs and zero Params.
663552.0 162.0
from __future__ import print_function, division
import os
import time
import torch
import torchvision
from torchvision import datasets, models, transforms
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
data_dir = "data/archive/data"
input_shape = 224
mean = [0.5, 0.5, 0.5]
std = [0.5, 0.5, 0.5]
#data transformation
data_transforms = {
'train': transforms.Compose([
transforms.CenterCrop(input_shape),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
'validation': transforms.Compose([
transforms.CenterCrop(input_shape),
transforms.ToTensor(),
transforms.Normalize(mean, std)
]),
}
image_datasets = {
x: datasets.ImageFolder(
os.path.join(data_dir, x),
transform=data_transforms[x]
)
for x in ['train', 'validation']
}
dataloaders = {
x: torch.utils.data.DataLoader(
image_datasets[x], batch_size=32,
shuffle=True, num_workers=0
)
for x in ['train', 'validation']
}
dataset_sizes = {x: len(image_datasets[x]) for x in ['train', 'validation']}
class_names = image_datasets['train'].classes
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
images, labels = next(iter(dataloaders['train']))
rows = 4
columns = 4
fig=plt.figure()
for i in range(16):
fig.add_subplot(rows, columns, i+1)
plt.title(class_names[labels[i]])
img = images[i].numpy().transpose((1, 2, 0))
img = std * img + mean
plt.imshow(img)
plt.show()
## Load the model based on VGG19
vgg_based = torchvision.models.vgg19(pretrained=True)
## freeze the layers
for param in vgg_based.parameters():
param.requires_grad = False
# Modify the last layer
number_features = vgg_based.classifier[6].in_features
features = list(vgg_based.classifier.children())[:-1] # Remove last layer
features.extend([torch.nn.Linear(number_features, len(class_names))])
vgg_based.classifier = torch.nn.Sequential(*features)
vgg_based = vgg_based.to(device)
print(vgg_based)
criterion = torch.nn.CrossEntropyLoss()
optimizer_ft = optim.SGD(vgg_based.parameters(), lr=0.001, momentum=0.9)
def train_model(model, criterion, optimizer, num_epochs=25):
since = time.time()
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# set model to trainable
# model.train()
train_loss = 0
# Iterate over data.
for i, data in enumerate(dataloaders['train']):
inputs, labels = data
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(True):
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
print('{} Loss: {:.4f}'.format(
'train', train_loss / dataset_sizes['train']))
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
return model
def visualize_model(model, num_images=6):
was_training = model.training
model.eval()
images_so_far = 0
fig = plt.figure()
with torch.no_grad():
for i, (inputs, labels) in enumerate(dataloaders['validation']):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
for j in range(inputs.size()[0]):
images_so_far += 1
ax = plt.subplot(num_images // 2, 2, images_so_far)
ax.axis('off')
ax.set_title('predicted: {} truth: {}'.format(class_names[preds[j]], class_names[labels[j]]))
img = inputs.cpu().data[j].numpy().transpose((1, 2, 0))
img = std * img + mean
ax.imshow(img)
if images_so_far == num_images:
model.train(mode=was_training)
return
model.train(mode=was_training)
vgg_based = train_model(vgg_based, criterion, optimizer_ft, num_epochs=1)
visualize_model(vgg_based)
plt.show()- CNN卷积核与通道讲解
- 多通道卷积过程,应该是输入一张三通道的图片,这时有多个卷积核进行卷积,并且每个卷积核都有三通道,分别对这张输入图片的三通道进行卷积操作。每个卷积核,分别输出三个通道,这三个通道进行求和,得到一个featuremap,有多少个卷积核,就有多少个featuremap
- 卷积神经网络中用
1*1卷积有什么作用或者好处呢? - 机器学习中正则化项L1和L2的直观理解




