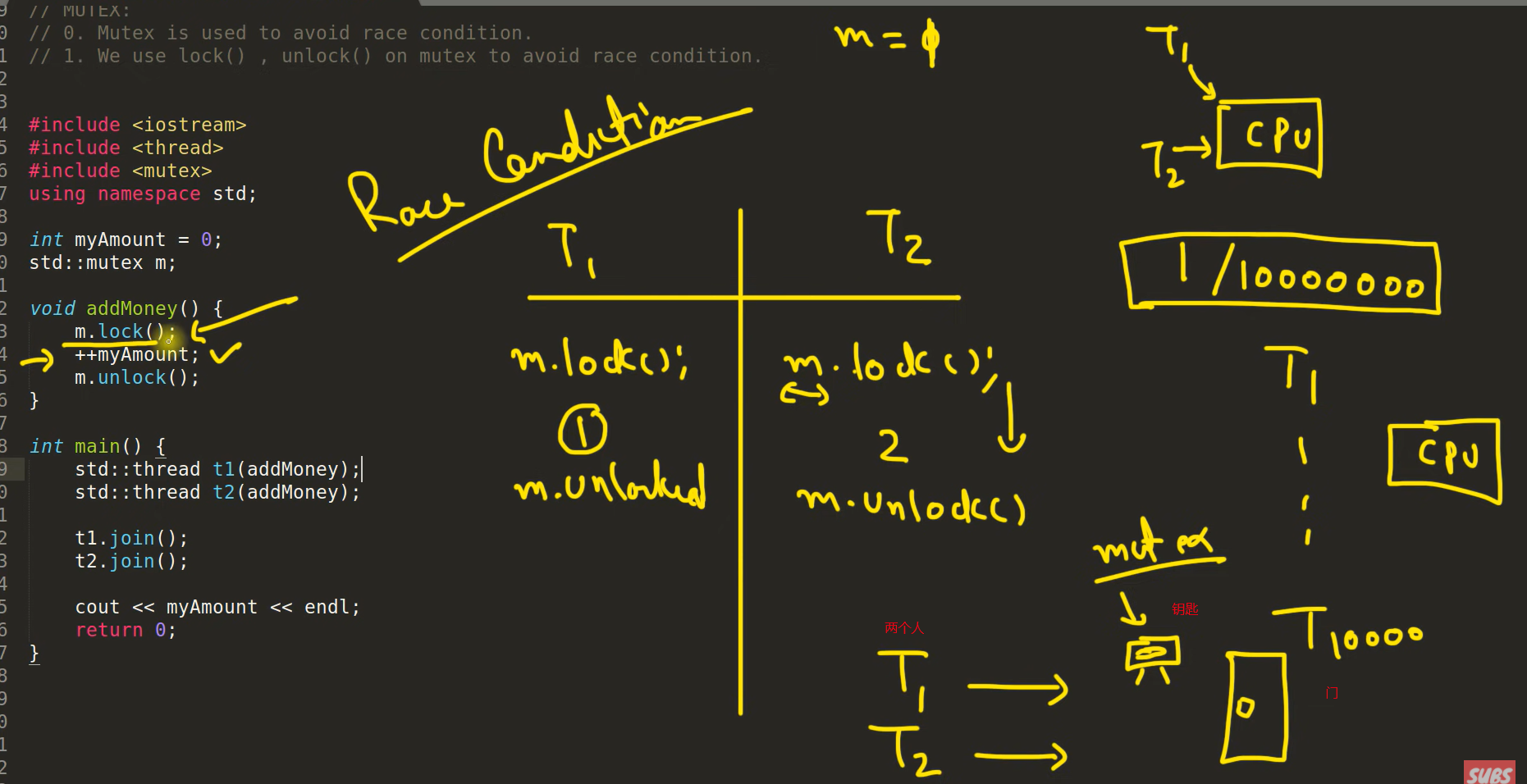
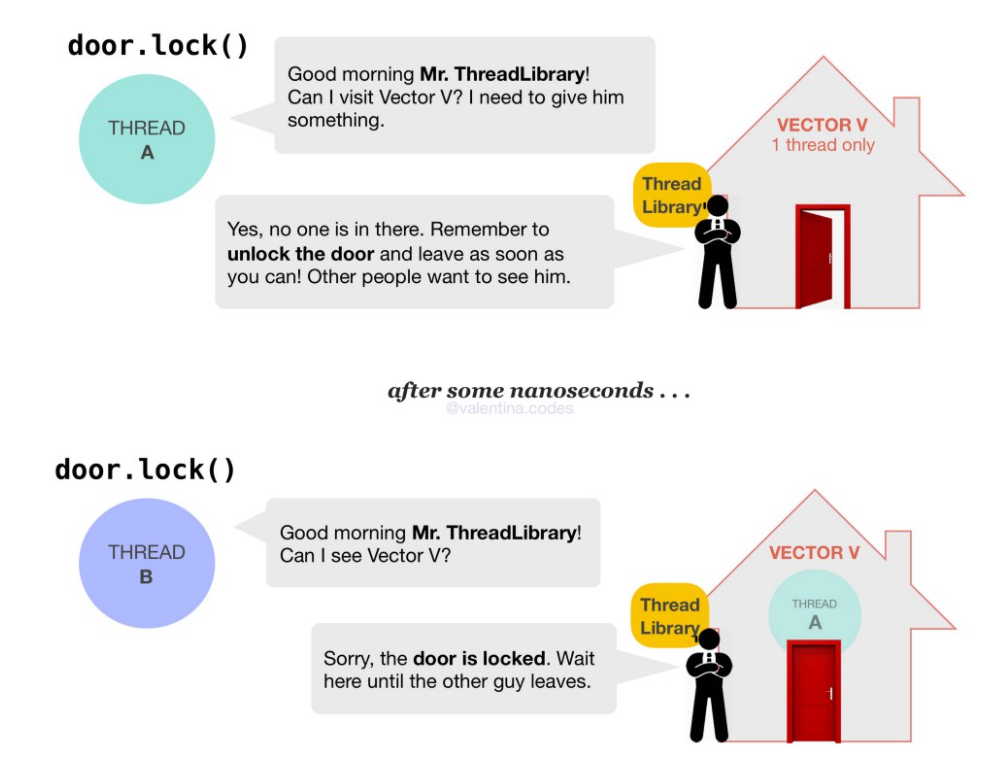
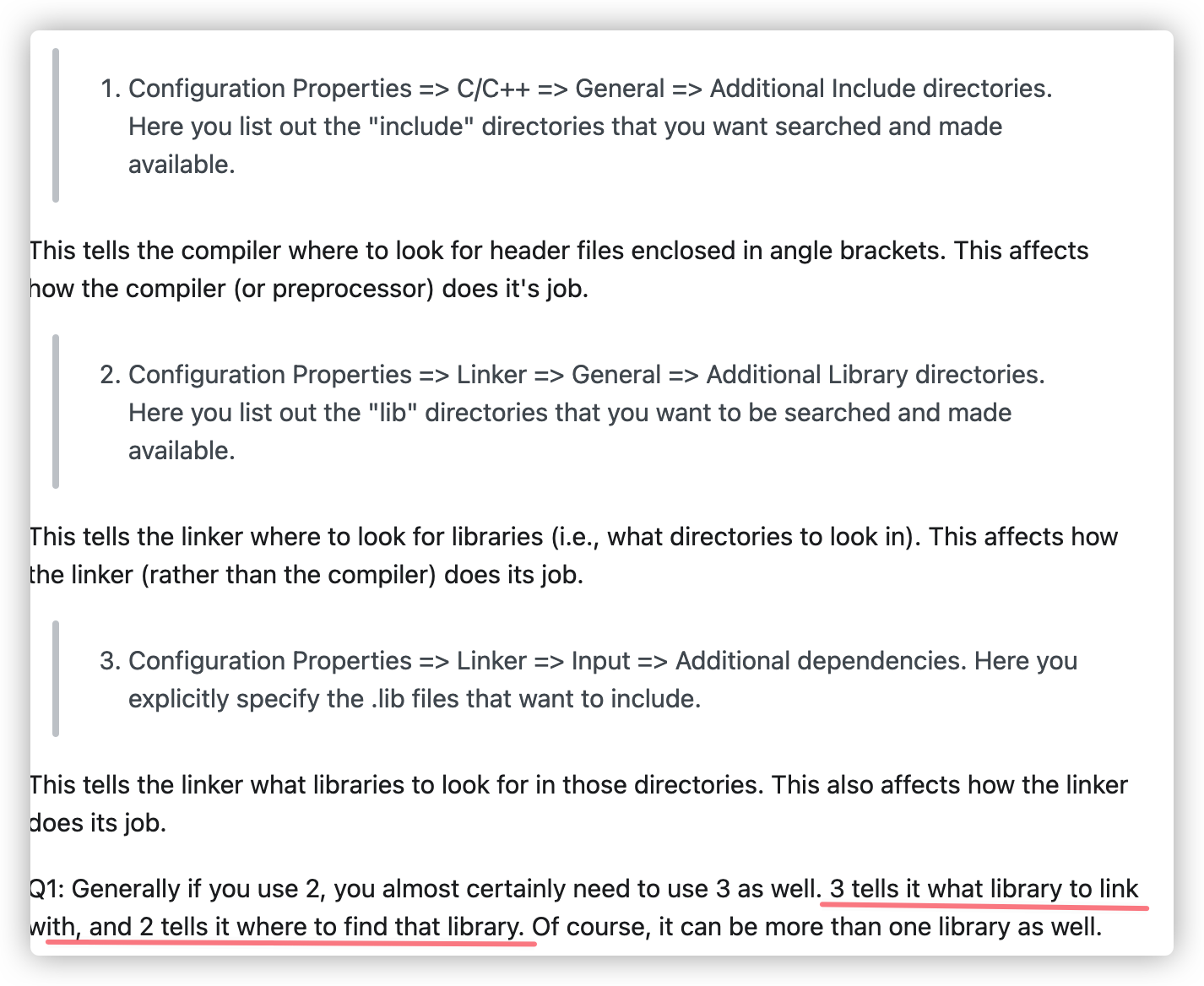
- 菜鸟教程
- 安装CLion(2020版,2021版(提取码1111))及配置
基础教程
函数
参数默认值
- 默认情况下,C++ 使用传值调用来传递参数。一般来说,这意味着函数内的代码不能改变用于调用函数的参数。
- 当定义一个函数,可以为参数列表中后边的每一个参数指定默认值。当调用函数时,如果实际参数的值留空,则使用这个默认值。
指针调用
- 向函数传递参数的指针调用方法,把参数的地址复制给形式参数。在函数内,该地址用于访问调用中要用到的实际参数。这意味着,修改形式参数会影响实际参数
#include <iostream>
using namespace std;
void change(int *x,int *y){
int tmp=*x;
*x=*y;
*y=tmp;
}
int main(){
int a=1;
int b=2;
change(&a,&b);
cout<<a<<"\t"<<b<<endl; // 2 1
}引用调用
- 该方法把参数的引用赋值给形式参数。在函数内,该引用用于访问调用中要用到的实际参数。这意味着,修改形式参数会影响实际参数
#include <iostream>
using namespace std;
void change(int &x,int &y){
int tmp=x;
x=y;
y=tmp;
}
int main(){
int a=1;
int b=2;
change(a,b);
cout<<a<<"\t"<<b<<endl; // 2 1
}Lambda 函数与表达式
Lambda函数的语法定义如下:
[capture](parameters) mutable ->return-type{statement}其中:
- [capture]:捕捉列表。捕捉列表总是出现在 lambda 表达式的开始处。事实上,[] 是 lambda 引出符。编译器根据该引出符判断接下来的代码是否是 lambda 函数。捕捉列表能够捕捉上下文中的变量供 lambda 函数使用(若某个参数不写到捕获列表中,则在lambda函数中不能用该参数,当然啦,自己的参数列表除外)。
- (parameters):参数列表。与普通函数的参数列表一致。如果不需要参数传递,则可以连同括号 () 一起省略。
- mutable:mutable 修饰符。默认情况下,lambda 函数总是一个 const 函数,mutable 可以取消其常量性。若使用该修饰符时,参数列表不可省略(即使参数为空),表示lambda会修改捕获的参数。
- >return_type:返回类型。用追踪返回类型形式声明函数的返回类型。出于方便,不需要返回值的时候也可以连同符号 -> 一起省略。此外,在返回类型明确的情况下,也可以省略该部分,让编译器对返回类型进行推导。不明确时,必须指定返回类型
- {statement}:函数体。内容与普通函数一样,不过除了可以使用参数之外,还可以使用所有捕获的变量。
在 lambda 函数的定义式中,参数列表和返回类型都是可选部分,而捕捉列表和函数体都可能为空,C++ 中最简单的 lambda 函数只需要声明为[]{};
// C++ program to demonstrate lambda expression in C++
#include <bits/stdc++.h>
using namespace std;
// Function to print vector
void printVector(vector<int> v) {
// lambda expression to print vector
for_each(v.begin(), v.end(), [](int i) {
std::cout << i << " ";
});
cout << endl;
}
int main() {
vector<int> v{4, 1, 3, 5, 2, 3, 1, 7};
printVector(v);
// below snippet find first number greater than 4
// find_if searches for an element for which
// function(third argument) returns true
vector<int>::iterator p = find_if(v.begin(), v.end(), [](int i) {
return i > 4;
});
cout << "First number greater than 4 is : " << *p << endl;
// function to sort vector, lambda expression is for sorting in
// non-decreasing order Compiler can make out return type as
// bool, but shown here just for explanation
sort(v.begin(), v.end(), [](const int &a, const int &b) -> bool {
return a > b;
});
printVector(v);
// function to count numbers greater than or equal to 5
int count_5 = count_if(v.begin(), v.end(), [](int a) {
return (a >= 5);
});
cout << "The number of elements greater than or equal to 5 is : "
<< count_5 << endl;
// function for removing duplicate element (after sorting all
// duplicate comes together)
p = unique(v.begin(), v.end(), [](int a, int b) {
return a == b;
});
// resizing vector to make size equal to total different number
v.resize(distance(v.begin(), p));
printVector(v);
// accumulate function accumulate the container on the basis of
// function provided as third argument
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int f = accumulate(arr, arr + 10, 1, [](int i, int j) {
return i * j;
});
cout << "Factorial of 10 is : " << f << endl;
// We can also access function by storing this into variable
auto square = [](int i) {
return i * i;
};
cout << "Square of 5 is : " << square(5) << endl;
int sum_of_elems = 0;
vector<int> vv{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
for_each(vv.begin(), vv.end(), [&](int n) {
sum_of_elems += n;
});
cout << "sum_of_elems is: " << sum_of_elems;
}
数组
指向数组的指针
- 数组名对应的是数组中第一个元素的地址
int main() {
int arr[] = {1, 2, 3};
cout << arr << endl; // 0x61fe14
}
- 若把第一个元素的地址存储在 指针p 中,则可以使用
*p、*(p+1)、*(p+2)等来访问数组元素
#include <iostream>
using namespace std;
int main() {
int arr[5]={0,1,2,3,4};
int *p=arr;
// 等价于
// int *p;
// p=arr;
for (int i = 0; i < 5; ++i) {
cout<<*(p+i)<<endl;// 利用指针,依次输出arr中的值
}
cout<<endl;
for (int i = 0; i < 5; ++i) {
cout<<*(arr+i)<<endl; //利用指针,依次输出arr中的值
cout<<arr[i]<<endl; //利用索引,依次输出arr中的值
}
}- C++ 对 char 型数组做了特殊规定,直接输出首地址时,会输出数组内容。如果想得到地址,可采用 &
#include <iostream>
using namespace std;
int main(){
char name[] = {"hello world"};
cout << name << endl; // 输出 hello world
cout << name[0] << endl; // 输出 h
cout << &name << endl; // 输出 0x61fe14
return 0;
}- C++ 中,将 char * 或 char[] 传递给 cout 进行输出,结果会是整个字符串,如果想要获得字符串的地址(第一个字符的内存地址),可使用以下方法:
- 强制转化为其他指针(非 char)。可以是 `void ,int ,float , double `等。 使用 &s[0] 不能输出 s[0](首字符)的地址。因为 &s[0] 将返回 char,对于 char(char 指针),cout 会将其作为字符串来处理,向下查找字符并输出直到字符结束 *
#include <iostream>
using namespace std;
const int MAX = 3;
int main ()
{
char var[MAX] = {'a', 'b', 'c'};
char *ptr;
// 指针中的数组地址
ptr = var;
for (int i = 0; i < MAX; i++)
{
cout << "Address of var[" << i << "] = ";
cout << (int *)ptr << endl; // 强制转化成其他类型的指针
cout << "Value of var[" << i << "] = ";
cout << *(ptr+i) << endl;
}
return 0;
}
//Address of var[0] = 0x61fe0d
//Value of var[0] = a
// Address of var[1] = 0x61fe0d
//Value of var[1] = b
// Address of var[2] = 0x61fe0d
//Value of var[2] = c传递数组给函数
- 如果想要在函数中传递一个一维数组作为参数,必须以下面三种方式来声明函数形式参数,这三种声明方式的结果是一样的,因为每种方式都会告诉编译器将要接收一个整型指针。(_实参可以是数组名_)
- 形参是一个指针
void myFunction(int *param) - 形参是一个已定义大小的数组
void myFunction(int param[10]) - 形参是一个未定义大小的数组
void myFunction(int param[])
- 形参是一个指针
# include <iostream>
using namespace std;
//这三种形参都可以
//double avgFunc(int arr[5],int size)
//double avgFunc(int arr[],int size)
double avgFunc(int *arr,int size){
int res=0;
for (int i = 0; i < size; ++i) {
res+=*(arr+i); //等价于res+=arr[i];
}
// 这里要强制转化一下res,否则除法返回的类型为舍去小数的整数 如 5/2=2
return double(res)/size;
}
int main(){
int arr[]={1,1,2,3,4};
double avg=avgFunc(arr,5);
cout<<avg<<endl;
}从函数返回数组
- C++ _不允许_返回一个完整的数组作为函数的参数。但是可以通过指定不带索引的数组名来返回一个指向数组的指针(也就是说,C++中函数是不能直接返回一个数组的,但是数组其实就是指针,所以可以让函数返回指针来实现)。如果想要从函数返回一个一维数组,必须声明一个返回指针的函数。另外,C++ 不支持在函数外返回局部变量的地址,除非定义局部变量为 static 变量
#include <iostream>
#include <cstdlib>
#include <ctime>
using namespace std;
// 要生成和返回随机数的函数
// 声明一个返回指针的函数
int *getArray() {
static int r[2] = {1, 2};
for (int i = 0; i < 2; ++i) {
cout << r[i] << endl;
}
return r;
}
// 要调用上面定义函数的主函数
int main() {
// 一个指向整数的指针
int *p;
p = getArray();
for (int i = 0; i < 2; i++) {
cout << "*(p + " << i << ") : ";
cout << *(p + i) << endl;
}
return 0;
}
//output:
//1
//2
//*(p + 0) : 1
//*(p + 1) : 2字符串
C风格字符串
- C 风格的字符串起源于 C 语言,并在 C++ 中继续得到支持。字符串实际上是使用 null 字符 \0 终止的一维字符数组。下面的声明和初始化创建了一个 RUNOOB 字符串。由于在数组的末尾存储了空字符,所以字符数组的大小比单词 RUNOOB 的字符数多一个
char site[7] = {'R', 'U', 'N', 'O', 'O', 'B', '\0'}; 可以写成char site[] = "RUNOOB";site[7]的结果为0
#include <iostream>
#include <cstring>
using namespace std;
int main()
{
char site[7] = {'R', 'U', 'N', 'O', 'O', 'B', '\0'};
char site1[] = "RUNOOB";
// 输出均为空白
cout<<site[6]<<endl;
cout<<site1[6]<<endl;
// 长度均为6
cout<<strlen(site)<<endl;
cout<<strlen(site1)<<endl;
}C++ String类
- 该类提供了更丰富的功能以及常用的操作
指针
指针数组
(务必看该部分的菜鸟网站笔记)
- 数组中存放的是(指向char,int等类型的 )的指针
- 可以用一个指向字符的指针数组来存储一个字符串列表
由于 C++ 运算符的优先级中,* 小于 [],所以 ptr 先和 [] 结合成为数组,然后再和 int 结合形成数组的元素类型是 int 类型,得到一个叫一个数组的元素是指针,简称指针数组。
int (ptr[3]);
这个和上面的一样,**优先级顺序是 小于 ()*,() 等于 []。ptr 先和 [] 结合成为数组,然后再和 int 结合形成数组的元素类型是 int * 类型,得到一个叫一个数组的元素是指针。int (ptr)[3];
这个就不一样了,优先级顺序是 小于 (),() 等于 [],() 和 [] 的优先级一样,但是结合顺序是从左到右,所以先是 () 里的 和 ptr 结合成为一个指针,然后是 (ptr) 和 [] 相结合成为一个数组,最后叫一个指针 ptr 指向一个数组,简称数组指针。
#include <iostream>
using namespace std;
const int MAX = 4;
int main(int argc, const char *argv[]) {
const char *names[MAX] = {
"Zara Ali",
"Hina Ali",
"Nuha Ali",
"Sara Ali",
};
for (int i = 0; i < MAX; i++) {
cout << " --- names[i] = " << names[i] << endl;
cout << " --- *names[i] = " << *names[i] << endl;
cout<<"----------------"<<endl;
}
return 0;
}
//--- names[i] = Zara Ali
//--- *names[i] = Z
//----------------
//--- names[i] = Hina Ali
//--- *names[i] = H
//----------------
//--- names[i] = Nuha Ali
//--- *names[i] = N
//----------------
//--- names[i] = Sara Ali
//--- *names[i] = S
//----------------传递指针给函数
- 定义函数时,声明函数形参为指针类型,实参是一个地址
#include <iostream>
using namespace std;
//定义函数时,声明函数形参为指针类型
void changeNum(int *p) {
*p = 2;
}
int main(int argc, const char *argv[]) {
int a = 1;
changeNum(&a);
cout << a; //结果为2
}引用
- 把引用作为返回值:通过使用引用来替代指针,会使 C++ 程序更容易阅读和维护。C++ 函数可以返回一个引用,方式与返回一个指针类似
#include <iostream>
using namespace std;
int arr[]={0,1,2,3,4};
//改变特定位置的数字,函数返回一个引用
int & changeNum(int i){
int &r=arr[i];// 给全局变量中的一个元素起个别名 r,返回r
return r;
}
int main(){
int size=sizeof (arr)/sizeof (arr[0]); //5
// 结果为01234
for (int i = 0; i < size; ++i) {
cout<<arr[i];
}
cout<<endl;
// 改变第0个位置的值,结果为 11234
int &tmp= changeNum(0); // 这里要为引用,否则结果仍然为01234
tmp=1;
for (int i = 0; i < size; ++i) {
cout<<arr[i];
}
}
数据结构
- 数据结构是 C++ 中另一种用户自定义的可用的数据类型,它允许存储不同类型的数据项
将结构体应用于函数时,通过与普通类型的变量进行类比,可以更好地理解
- e.g., 普通类型中,有
int a (或者 int *a), 则在结构体中,有Student stu (或者 Student *stu)- 以_类比_的方式来讲,
int与Student同等地位,变量名称a与变量名称stu同等地位 (实际上是int与sturct Student同等地位,但是struct可以省略)
结构作为函数参数
- 主函数中,定义结构体的变量s1,并传到函数中
- 在形参中,声明变量的类型 (如
void printStudent( Student stu))
# include <iostream>
using namespace std;
struct Student{
string name;
int age;
};
//形参中,stu的数据类型为 Student
// 写成 void printStudent(struct Student stu) 也可以
void printStudent( Student stu){
cout<<stu.name<<endl;
cout<<stu.age<<endl;
}
int main(){
// 定义结构体类型为Student的变量 s1
Student s1;
s1.name="Amy";
s1.age=10;
// 把s1变量传到函数中
printStudent(s1);
}
//Amy
//10指向结构的指针
- 主函数中,定义结构体的变量s1,并把s1的地址传到函数中
- 在形参中,声明变量的类型 (如
void printStudent( Student *stu),是student类型的stu)
# include <iostream>
using namespace std;
struct Student{
string name;
int age;
};
//这里的形参为指向结构的指针
void printStudent( Student *stu){
cout<<stu->name<<endl;
cout<<stu->age<<endl;
}
int main(){
Student s1;
s1.name="Amy";
s1.age=10;
printStudent(&s1); //把数据结构的s1变量的地址传递给函数
}
//output:
//Amy
//10向量中存放结构体
#include <iostream>
#include <vector>
using namespace std;
struct data_config {
int m_freq;
vector<int> m_dis_near;
vector<int> m_dis_far;
string m_path;
} my_data1, my_data2;
int main() {
my_data1.m_freq = 20;
my_data1.m_dis_near = vector<int>{20, 30, 40};
my_data1.m_dis_far = vector<int>{2, 3, 4};
my_data1.m_path = "this is my 20 path";
my_data2.m_freq = 50;
my_data2.m_dis_near = vector<int>{80, 90, 100};
my_data2.m_dis_far = vector<int>{21, 31, 41};
my_data2.m_path = "this is my 50 path";
vector<data_config> all_data_config={my_data1, my_data2};
// int tmp = all_data_config.size();
for (auto &i: all_data_config) {
cout << i.m_freq << endl;
cout << i.m_path << endl;
cout << "===" << endl;
}
}
面向对象
类&对象
头文件、源文件、主文件书写
- 头文件定义类和函数申明
#include <iostream>
class Box{
public:
int x;
int y;
int z;
int get();
void set(int a, int b,int c);
};- 源文件实现函数
#include "Box.h"
int Box::get() {
return x*y*z;
}
void Box::set(int a, int b,int c) {
x=a;
y=b;
z=c;
}
- 主文件调用函数
#include <iostream>
#include "Box.h"
using namespace std;
int main(){
Box b1;
Box b2;
b1.x=1;
b1.y=2;
b1.z=3;
b2.set(1,2,3);
cout<<b1.get()<<endl;
cout<<b2.get()<<endl;
}
作用域符解析
作用域运算符为::,它用于以下目的:
- 当存在具有相同名称的局部变量时,要访问全局变量
- 在类之外定义函数
- 访问一个类的静态变量
- 如果有多个继承:如果两个祖先类中存在相同的变量名,则可以使用作用域运算符进行区分
- 对于命名空间:如果两个命名空间中都存在一个具有相同名称的类,则可以将名称空间名称与作用域解析运算符一起使用,以引用该类而不会发生任何冲突
- 在另一个类中引用一个类:如果另一个类中存在一个类,我们可以使用嵌套类使用作用域运算符来引用嵌套的类
类访问修饰符
如果继承时不显示声明是 private,protected,public 继承,则默认是 private 继承,在 struct 中默认 public 继承
public 继承:基类 public 成员,protected 成员,private 成员的访问属性在派生类中分别变成:public, protected, private
protected 继承:基类 public 成员,protected 成员,private 成员的访问属性在派生类中分别变成:protected, protected, private
private 继承:基类 public 成员,protected 成员,private 成员的访问属性在派生类中分别变成:private, private, private
但无论哪种继承方式,都有:
- private 成员只能被本类成员(类内)和友元访问,不能被派生类访问
- protected 成员可以被派生类访问
- 类外都不能访问private(除非友元)和protected成员
构造函数 & 析构函数
- 构造函数是类的一种特殊的成员函数,它会在每次创建类的新对象时执行
- 构造函数的名称与类的名称是完全相同的,并且不会返回任何类型,也不会返回 void。构造函数可用于为某些成员变量设置初始值(默认的构造函数没有任何参数,但如果需要,构造函数也可以带有参数。这样在创建对象时就会给对象赋初始值)
- 构造器中,初始化顺序最好要与变量在类声明的顺序一致(否则可能出错)
该例子中包含无参/有参构造器。通过带参数的构造器对对象进行初始化,然后用setAge和getAge重新设置并访问私有变量age
#include<iostream>
#include <string>
using namespace std;
class Student {
private:
int age; // 把age设为private变量
public:
string name;
//通过getAge和setAge函数访问私有变量成员:可以在setAge中设一些限制,如年龄范围等
int getAge() const;
void setAge(int age);
//带有参数的构造器,可以对Student中的变量进行初始化
Student(int age, const string &name);
Student();
};
//访问私有变量age
int Student::getAge() const {
return age;
}
//设置私有变量(并可对该变量加一些限制)
void Student::setAge(int age) {
if (age < 0 || age > 200)
cout << "invalid age" << endl;
else
Student::age = age;
}
//不带参数的构造器
Student::Student() {}
//带有参数的构造器,可以对对象进行初始化
Student::Student(int age, const string &name) : age(age), name(name) {}
int main() {
// 通过有参构造器初始化对象s1,输出年龄和名字
Student s1(18, "Amy");
cout << "S1: " << s1.getAge() << '\t' << s1.name << endl;
// 初始化对象s2, 默认调用无参构造器,然后设置变量值
Student s2;
s2.setAge(19);
s2.name = "Bob";
cout << "S2: " << s2.getAge() << '\t' << s2.name << endl;
// 初始化对象s3,根据函数重载规则,调用有参构造器
Student s3(19, "Tom");
// 重新设置s3的年龄和名字
s3.setAge(20);
s3.name = "Amy's brother";
cout << "S3: " << s3.getAge() << '\t' << s3.name << endl;
}
//S1: 18 Amy
//S2: 19 Bob
//S3: 20 Amy's brother
- 析构函数是类的一种特殊的成员函数,它会在每次删除所创建的对象时执行,一个类的析构函数只能有一个
- 析构函数的名称与类的名称是完全相同的,只是在前面加了个波浪号(~)作为前缀,它不会返回任何值,也不能带有任何参数。析构函数有助于在跳出程序(比如关闭文件、释放内存等)前释放资源
#include<iostream>
#include <string>
using namespace std;
class Student {
public:
string name;
Student() {
cout << "Construct:Object is being created" << endl;
}
virtual ~Student() {
cout << "Construct:Object is being deleted" << endl;
}
};
int main() {
Student s1;
s1.name = "Amy";
cout << s1.name << endl;
}
//Construct:Object is being created
//Amy
//Construct:Object is being deleted拷贝构造函数
- Q:为什么需要拷贝构造函数?
- A:把参数传递给函数有三种方法,一种是传值,一种是传地址,一种是传引用。传值与其他两种方式不同的地方在于: 当使用传值方式的时候,会在函数里面生成传递参数的一个副本,这个副本的内容是按位从原始参数那里复制过来的,两者的内容是相同的。当原始参数是一个类的对象时,它也会产生一个对象的副本,此时需要注意:一般对象在创建时都会调用构造函数来进行初始化,但是在产生对象的副本时如果再执行对象的构造函数,那么这个对象的属性又再恢复到原始状态,这就不是我们希望的了。所以在产生对象副本的时候,构造函数不会被执行,被执行的是一个默认的拷贝构造函数
拷贝构造函数是一种特殊的构造函数,它在创建对象时,是使用同一类中之前创建的对象来初始化新创建的对象。拷贝构造函数通常用于(即:需要生成对象的副本):
- 通过使用另一个同类型的对象来初始化新创建的对象
- 复制对象把它作为参数传递给函数
- 复制对象,并从函数返回这个对象
如果在类中没有定义拷贝构造函数,编译器会自行定义一个。如果类带有指针变量,并有动态内存分配,则它必须有一个拷贝构造函数。
- Q:为什么类中带有指针变量,并有动态内存分配,则它必须有一个拷贝构造函数?
- A:默认的拷贝构造函数实现的只能是浅拷贝,即直接将原对象的数据成员值依次复制给新对象中对应的数据成员,并没有为新对象另外分配内存资源。这样,如果对象的数据成员是指针,两个指针对象实际上指向的是同一块内存空间。
在某些情况下,浅拷贝回带来数据安全方面的隐患。
当类的数据成员中有指针类型时,我们就必须定义一个特定的拷贝构造函数,该拷贝构造函数不仅可以实现原对象和新对象之间数据成员的拷贝,而且可以为新的对象分配单独的内存资源,这就是深拷贝构造函数。
- Q:如何防止默认拷贝发生?
- A:声明一个私有的拷贝构造函数,这样因为拷贝构造函数是私有的,如果用户试图按值传递或函数返回该类的对象,编译器会报告错误,从而可以避免按值传递或返回对象。
总结:
当出现类的等号赋值时,会调用拷贝函数,在未定义显式拷贝构造函数的情况下,系统会调用默认的拷贝函数——即浅拷贝,它能够完成成员的一一复制。当数据成员中没有指针时,浅拷贝是可行的。但当数据成员中有指针时,如果采用简单的浅拷贝,则两类中的两个指针将指向同一个地址,当对象快结束时,会调用两次析构函数,而导致指针悬挂现象。所以,这时,必须采用深拷贝。
深拷贝与浅拷贝的区别就在于深拷贝会在堆内存中另外申请空间来储存数据,从而也就解决了指针悬挂的问题。简而言之,当数据成员中有指针时,必须要用深拷贝。
#include <iostream>
using namespace std;
class Student {
public:
// 带参数的构造函数,用于初始化age
Student(int age);
//拷贝构造函数
Student(const Student &obj);
// 析构函数
virtual ~Student();
//得到年龄
int getAge();
private:
// 定义私有的指针 *p,并用它来访问age
int *p;
};
//指针访问age变量
Student::Student(int age) {
cout<<"调用构造函数"<<endl;
p = new int;
*p = age;
// 或者 : int *p=new int(age);
}
//拷贝构造函数时,指针内容 为 引用对象obj的指针内容
Student::Student(const Student &obj) {
cout<<"调用拷贝构造函数"<<endl;
p = new int;
*p = *obj.p;
}
Student::~Student() {
cout<<"调用析构函数"<<endl;
}
//返回指针指向的内容
int Student::getAge() {
return *p;
}
//调用还函数时,函数的形参为 一个对象 stu
void display(Student stu) {
cout << stu.getAge() << endl;
}
int main() {
Student s1(10);
display(s1);
cout << "================" << endl;
Student s2 = s1; //注意这里的对象初始化要调用拷贝构造函数,而非赋值
display(s2);
}
//调用构造函数
//调用拷贝构造函数
//10
//调用析构函数
//================
//调用拷贝构造函数
//调用拷贝构造函数
//10
//调用析构函数
//调用析构函数
//调用析构函数友元函数
友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定义中出现过,但是友元函数并不是成员函数
友元可以是一个函数,该函数被称为友元函数;友元也可以是一个类,该类被称为友元类,在这种情况下,整个类及其所有成员都是友元(声明类 ClassTwo 的所有成员函数作为类 ClassOne 的友元,需要在类 ClassOne 的定义中放置声明:
friend class ClassTwo;)如果要声明函数为一个类的友元,需要在类定义中该函数原型前使用关键字 friend。
因为友元函数没有this指针,则参数要有三种情况:
- 要访问非static成员时,需要对象做参数(如下面的例子中:
void printAge(Student stu)); - 要访问static成员或全局变量时,则不需要对象做参数;
- 如果做参数的对象是全局对象,则不需要对象做参数.
- 要访问非static成员时,需要对象做参数(如下面的例子中:
可以直接调用友元函数,不需要通过对象或指针
#include <iostream>
using namespace std;
class Student{
private:
int age; //私有变量
public:
void setAge(int age);
friend void printAge(Student stu); //在类中声明友元函数
};
void Student::setAge(int age) {
Student::age = age;
}
void printAge(Student stu){
cout<<stu.age<<endl; // 友元函数可以访问类的私有变量
}
int main(){
Student s1;
s1.setAge(10);
printAge(s1);// 10
}内联函数
- 内联函数是通常与类一起使用(通过内联函数,编译器试图在调用函数的地方扩展函数体中的代码)。引入内联函数的目的是为了解决程序中函数调用的效率问题。程序在编译器编译的时候,编译器将程序中出现的内联函数的调用表达式用内联函数的函数体进行替换,而对于其他的函数,都是在运行时候才被替代。这其实就是个空间代价换时间的节省。所以内联函数一般都是1-5行的小函数。在使用内联函数时要注意:不允许使用循环语句和开关语句
- 如果想把一个函数定义为内联函数,则需要在函数名前面放置关键字 inline,在调用函数之前需要对函数进行定义
- 在类定义中的定义的函数都是内联函数,即使没有使用 inline 说明符
#include <iostream>
using namespace std;
//内联函数
inline int Max(int x, int y) {
return (x > y) ? x : y;
}
// 程序的主函数
int main() {
cout << "Max (20,10): " << Max(20, 10) << endl;
cout << "Max (0,200): " << Max(0, 200) << endl;
cout << "Max (100,1010): " << Max(100, 1010) << endl;
return 0;
}
//Max (20,10): 20
//Max (0,200): 200
//Max (100,1010): 1010this 指针
- 每一个对象都能通过 this 指针来访问自己的地址。this 指针是所有成员函数的隐含参数。因此,在成员函数内部,它可以用来指向调用对象
友元函数没有 this 指针,因为友元不是类的成员。只有成员函数才有 this 指针
下面的例子,对象通过this指针访问自己的体积,并与其他对象的体积比较大小
#include <iostream>
using namespace std;
class Box {
private:
int x;
int y;
int z;
public:
// 定义构造函数,对x y z 赋初值
Box(int a, int b, int c) {
x = a;
y = b;
z = c;
};
//求体积
int volume() {
return x * y * z;
}
//比较当前体积和形参对应的体积哪个大
int compare(Box box) {
if (this->volume() > box.volume())
cout << "box1 is larger" << endl;
else
cout << "box2 is larger" << endl;
}
};
int main() {
Box box1(1,2,3);
Box box2(4,5,6);
box1.compare(box2);
}
//box2 is larger指向类的指针
指向类的指针与指向结构的指针类似,访问指向类的指针的成员,需要使用成员访问运算符 ->
#include <iostream>
using namespace std;
class Box {
private:
int x;
int y;
int z;
public:
// 定义构造函数,对x y z 赋初值
Box(int a, int b, int c) {
x = a;
y = b;
z = c;
};
//求体积
int volume() {
return x * y * z;
}
};
int main() {
Box box(1, 2, 3);
Box *p = &box; //定义指向类的指针p,并把对象的地址给了p
// 通过 指针p->成员 来访问成员
cout << p->volume() << endl;//6
}
类的静态成员
- 使用 static 关键字来把类成员定义为静态的。当我们声明类的成员为静态时,这意味着无论创建多少个类的对象,静态成员都只有一个副本 (一个银行当天创建了多个账户(对象),但这些账户对应的利率都是一样的,这个利率就可以类比为static变量;可能每天的利率都是变化的,所以static变量可以变化)
- 静态成员在类的所有对象中是共享的。如果不存在其他的初始化语句,在创建第一个对象时,所有的静态数据都会被初始化为零
- 我们不能把静态成员的初始化放置在类的定义中(类的static变量也不能在别的函数中对其初始化,但是定义在函数中的static变量可以在该函数或其他函数中初始化),但是可以在类的外部通过使用范围解析运算符 :: 来重新声明静态变量从而对它进行初始化
#include <iostream>
using namespace std;
class Box {
private:
int x;
int y;
int z;
public:
static int count; // 统计创建对象的个数
// 定义构造函数,对x y z 赋初值
Box(int a, int b, int c) {
x = a;
y = b;
z = c;
// 每创建一个对象,计数+1
count++;
};
};
int Box::count=0;
int main() {
Box box1(1, 2, 3);
cout << Box::count<< endl;//1
// 这时,static int 类型的 count已经存在了,所以就在之前的基础上+1
Box box2(1, 2, 3);
cout << Box::count<< endl;//2
}
- 静态成员函数
- 静态成员函数即使在类对象不存在的情况下也能被调用,静态函数只要使用类名加范围解析运算符
::就可以访问 - 静态成员函数只能访问静态成员数据、其他静态成员函数和类外部的其他函数
- 静态成员函数有一个类范围,他们不能访问类的 this 指针。可以使用静态成员函数来判断类的某些对象是否已被创建。
- 静态成员函数与普通成员函数的区别:
- 静态成员函数没有 this 指针,只能访问静态成员(包括静态成员变量和静态成员函数)
- 普通成员函数有 this 指针,可以访问类中的任意成员
- 静态成员函数即使在类对象不存在的情况下也能被调用,静态函数只要使用类名加范围解析运算符
继承
- 一个派生类继承了所有的基类方法(我们几乎不使用 protected 或 private 继承,通常使用 public 继承),但下列情况除外:
基类的构造函数、析构函数和拷贝构造函数
基类的重载运算符
基类的友元函数 - 多继承 (环状继承),A->D, B->D, C->(A,B),例如:
D
/ \
B A
\ /
C
class D{......};
class B: public D{......};
class A: public D{......};
class C: public B, public A{.....};
这个继承会使D创建两个对象,要解决上面问题就要用虚拟继承格式:class 类名: virtual 继承方式 父类名
class D{......};
class B: virtual public D{......};
class A: virtual public D{......};
class C: public B, public A{.....};重载运算符
- 可以重新定义或重载大部分 C++ 内置的运算符
- 重载的运算符是带有特殊名称的函数,函数名是由关键字 operator 和其后要重载的运算符符号构成的。与其他函数一样,重载运算符有一个返回类型和一个参数列表,如
Box operator+(const Box&); - 大多数的重载运算符可被定义为普通的非成员函数或者被定义为类成员函数
多态
形成多态必须具备三个条件:
必须存在继承关系
继承关系必须有同名虚函数(其中虚函数是在基类中使用关键字Virtual声明的函数,在派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数)
* 存在基类类型的指针或者引用,通过该指针或引用调用虚函数
#include <iostream>
using namespace std;
class Shape {
protected:
int width, height;
public:
Shape(int a = 0, int b = 0) {
width = a;
height = b;
}
int area() {
cout << "Parent class area :" << endl;
return 0;
}
};
class Rectangle : public Shape {
public:
Rectangle(int a = 0, int b = 0) : Shape(a, b) {}
int area() {
cout << "Rectangle class area :" << endl;
return (width * height);
}
};
class Triangle : public Shape {
public:
Triangle(int a = 0, int b = 0) : Shape(a, b) {}
int area() {
cout << "Triangle class area :" << endl;
return (width * height / 2);
}
};
// 程序的主函数
int main() {
Shape *shape;
Rectangle rec(10, 7);
Triangle tri(10, 5);
// 存储矩形的地址
shape = &rec;
// 调用矩形的求面积函数 area
shape->area();
// 存储三角形的地址
shape = &tri;
// 调用三角形的求面积函数 area
shape->area();
return 0;
}
//Parent class area
//Parent class area- 这个例子不能实现不同类型的面积求解。导致错误输出的原因是,调用函数 area() 被编译器设置为基类中的版本,这就是所谓的静态多态,或静态链接 - 函数调用在程序执行前就准备好了。有时候这也被称为早绑定,因为 area() 函数在程序编译期间就已经设置好了。
- 让我们对程序稍作修改,在 Shape 类中,area() 的声明前放置关键字 virtual就可以了。此时,编译器看的是指针的内容,而不是它的类型。因此,由于 tri 和 rec 类的对象的地址存储在 *shape 中,所以会调用各自的 area() 函数。每个子类都有一个函数 area() 的独立实现。这就是多态的一般使用方式。有了多态,可以有多个不同的类,都带有同一个名称但具有不同实现的函数,函数的参数甚至可以是相同的。这就引申出:虚函数
- 虚函数 是在基类中使用关键字 virtual 声明的函数。在派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数。我们想要的是在程序中任意点可以根据所调用的对象类型来选择调用的函数,这种操作被称为动态链接,或后期绑定
- 虚函数必须实现,如果不实现,编译器将报错
- 纯虚函数:想要在基类中定义虚函数,以便在派生类中重新定义该函数更好地适用于对象,但是在基类中又不能对虚函数给出有意义的实现,这个时候就会用到纯虚函数
virtual int area() = 0;,= 0告诉编译器,函数没有主体- 纯虚函数一定没有定义,纯虚函数用来规范派生类的行为,即接口。包含纯虚函数的类是抽象类,抽象类不能定义实例,但可以声明指向实现该抽象类的具体类的指针或引用
- 虚函数 是在基类中使用关键字 virtual 声明的函数。在派生类中重新定义基类中定义的虚函数时,会告诉编译器不要静态链接到该函数。我们想要的是在程序中任意点可以根据所调用的对象类型来选择调用的函数,这种操作被称为动态链接,或后期绑定
接口(抽象类)
- 接口描述了类的行为和功能,而不需要完成类的特定实现
- C++ 接口是使用抽象类来实现的,抽象类与数据抽象互不混淆,数据抽象是一个把实现细节与相关的数据分离开的概念。如果类中至少有一个函数被声明为纯虚函数,则这个类就是抽象类。纯虚函数是通过在声明中使用 “= 0” 来指定的,如
virtual double getVolume() = 0;。设计抽象类的目的是为了给其他类提供一个可以继承的适当的基类
高级教程
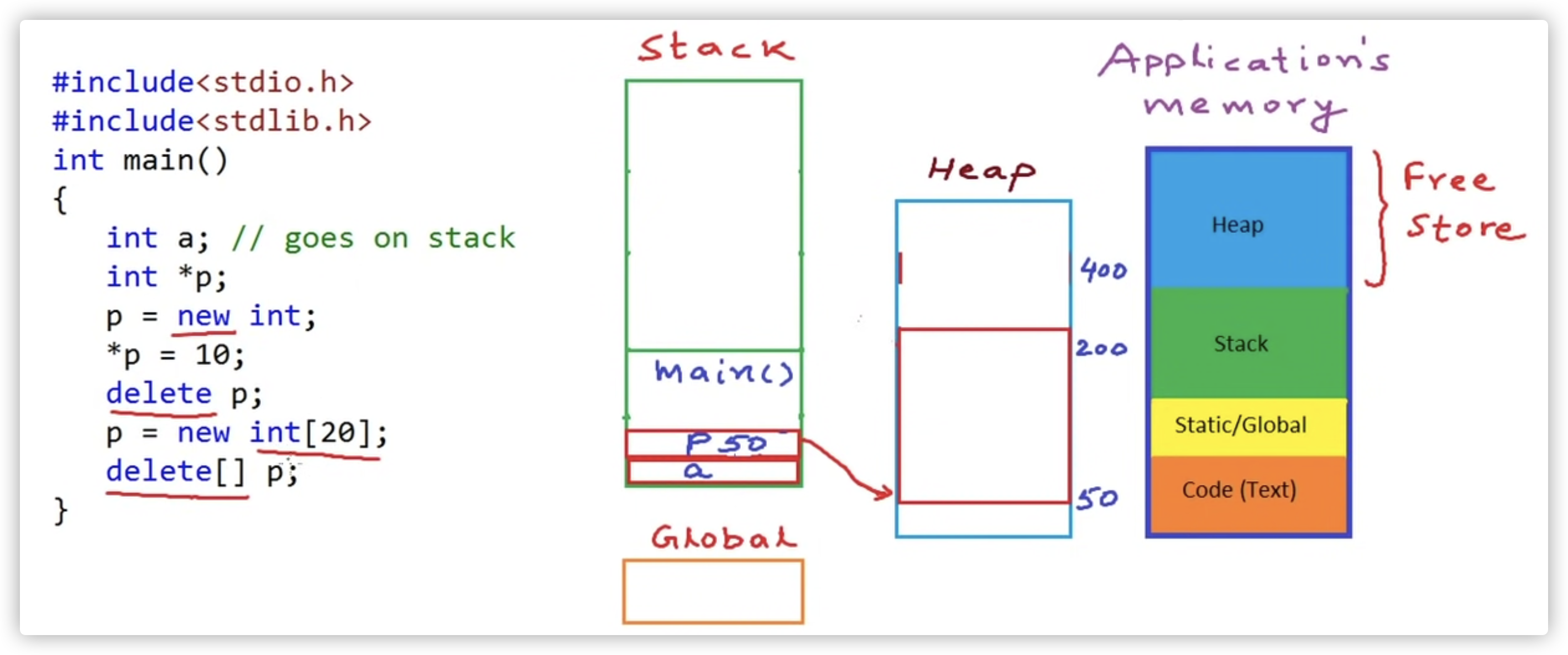
动态内存
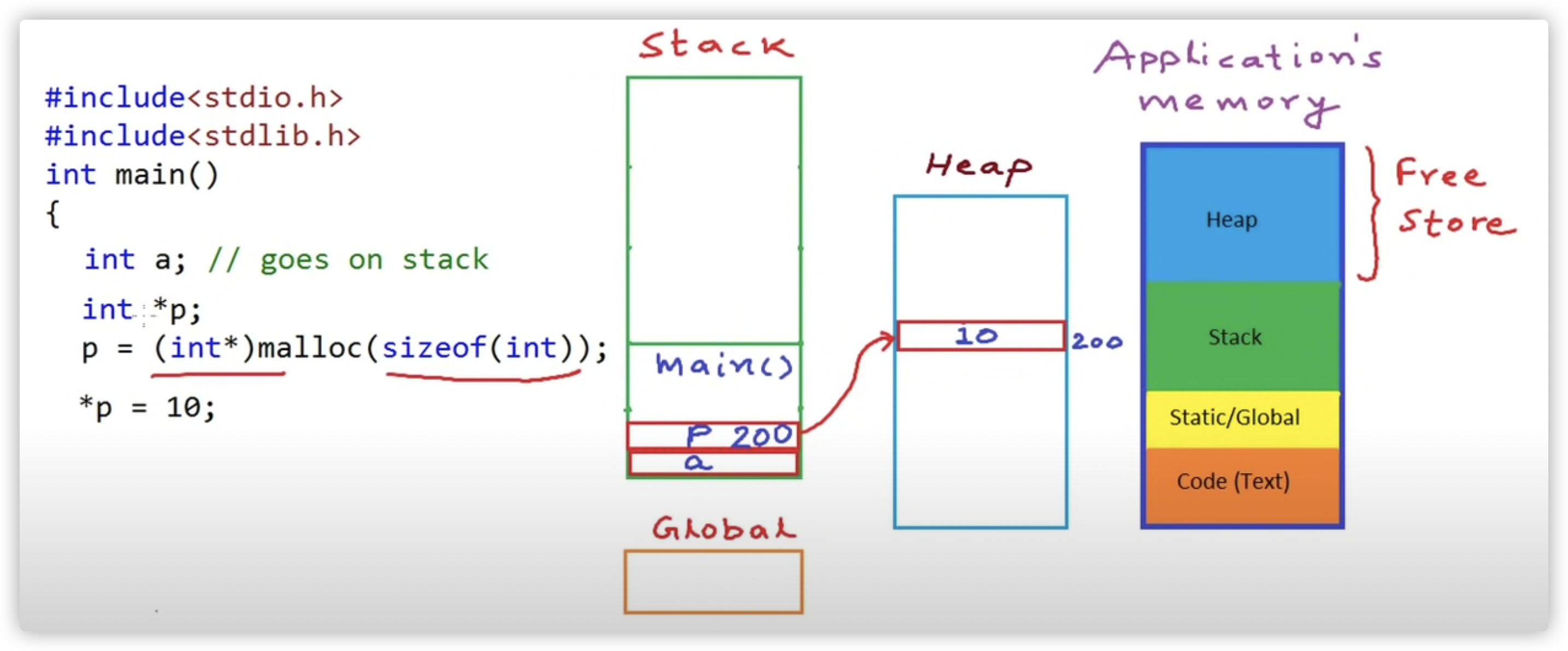
C++ 程序中的内存分为两个部分:
- 栈:在函数内部声明的所有变量都将占用栈内存
- 堆:这是程序中未使用的内存,在程序运行时可用于动态分配内存
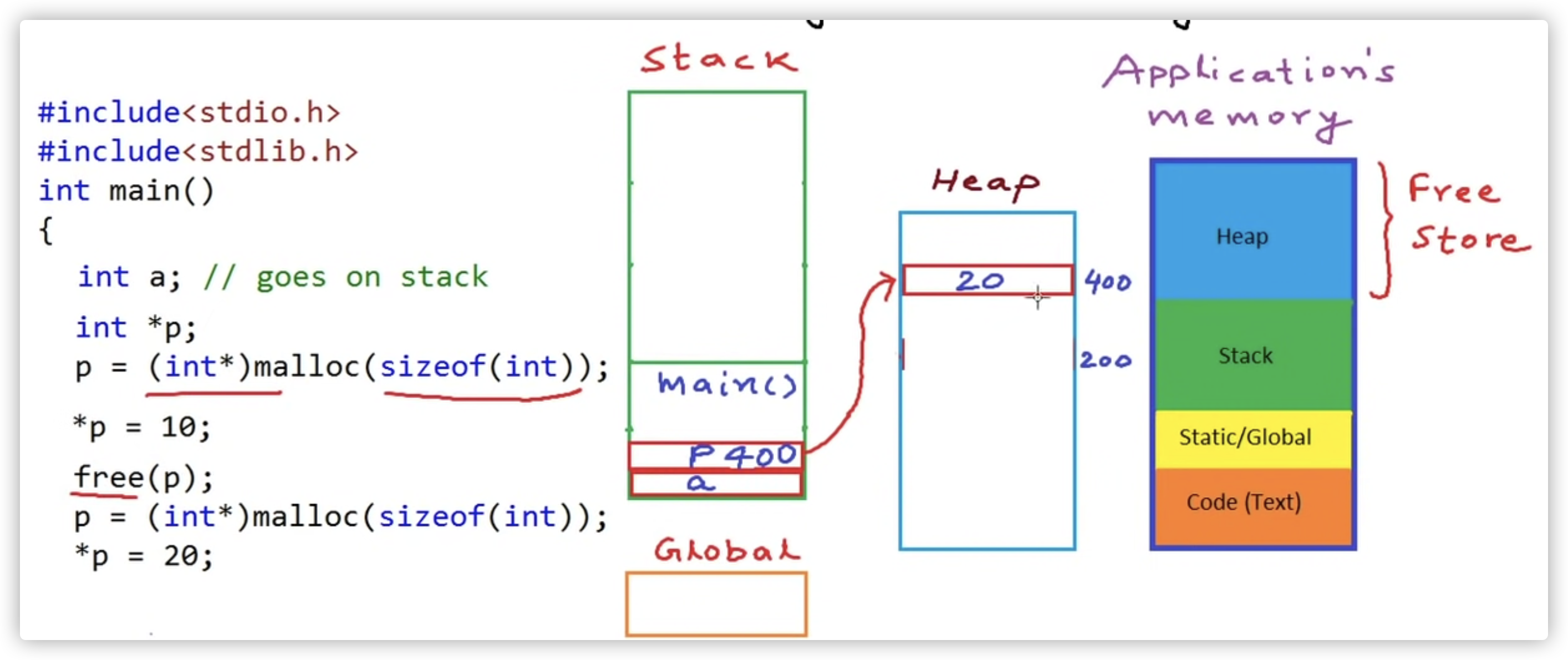
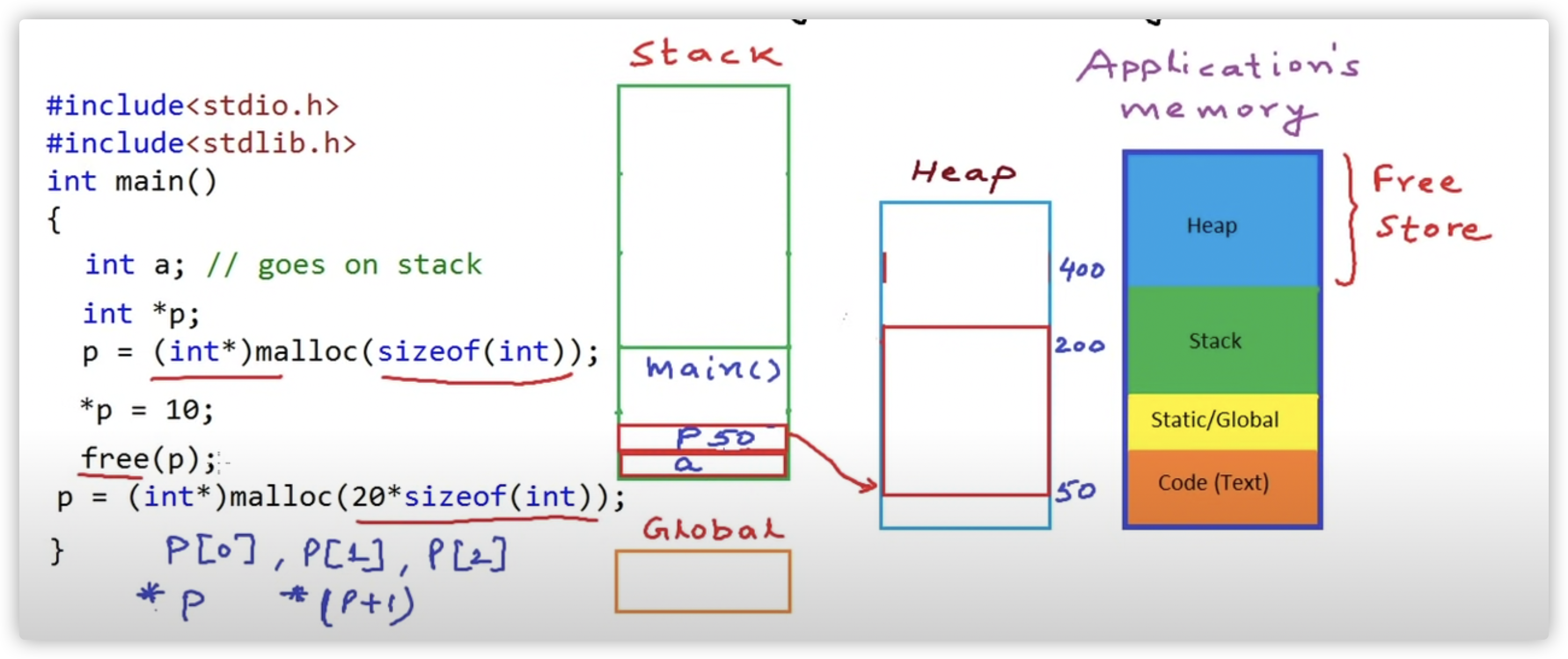
delete 与 delete[] 区别
- 如果ptr代表一个用new申请的内存返回的内存空间地址,即所谓的指针,那么:
- delete ptr – 代表用来释放内存,且只用来释放ptr指向的内存
- delete[] rg – 用来释放rg指向的内存,!!还逐一调用数组中每个对象的 destructor
对于像 int/char/long/int*/struct 等等简单数据类型,由于对象没有 destructor,所以用 delete 和 delete [] 是一样的!但是如果是C++ 对象数组就不同了!
- 如果ptr代表一个用new申请的内存返回的内存空间地址,即所谓的指针,那么:
命名空间
命名空间可作为附加信息来区分不同库中相同名称的函数、类、变量等。使用了命名空间即定义了上下文。本质上,命名空间就是定义了一个范围。
模板
- template中,引入 typename 和 class 关键字,它表明后面的符号为一个类型
- 如果需要代码分离,即 template class 的声明、定义,以及 main 函数分属不同文件。例如:
src_dir
|____MyStack.h
|____MyStack.cpp
|____main.cpp
则 main.cpp 文件中需要同时包含 .h 文件和 .cpp 文件,不然会出现链接错误。
// main.cpp
#include "MyStack.h"
#include "MyStack.cpp"
// 其他include
// main函数主体
函数模板
定义形式:
template <typename type> ret-type func-name(parameter list)
{
// 函数的主体
ret-type :返回类型
func-name:函数名称
}使用:
#include <iostream>
using namespace std;
template<typename T>
T const &Max(T &x, T &y) {
return x > y ? x : y;
}
int main() {
int a = 2, b = 1;
double c = 20.1, d = 10.0;
cout << Max(a, b) << endl;
cout << Max(c, d) << endl;
}
//2
//20.1类模板
定义形式
template <class type> class class-name {
// 类主体
}类模板和函数模板的使用示例
#include <iostream>
using namespace std;
//假设石头密度相同,则宽度_w与高度_h的乘积作为石头的重量
//类模板:Stone的_w, _h的类型可变。以int为例,实例化时,Stone<int> r1(2, 3);
template<typename U>
class Stone {
public:
// 构造函数
Stone(U w, U h) : _w(w), _h(h) {};
// 操作符重载,<比较的是两个石头,即:< 的左右两边是Stone类型的对象。返回bool值
bool operator<(const Stone &rhs) const { return (_w*_h) < (rhs._w*rhs._h); };
// 用myWeight()函数返回重量以供打印
U myWeight() const{
return _w*_h;
}
private:
U _w, _h;
};
//函数模板,根据推导的结果,T为Stone,返回的类型也是Stone类。于是调用重载操作符 Stone::operator<
template<typename T>
inline
const T& compare(const T& a, const T& b) {
return b < a ? b : a;
}
int main() {
Stone<int> r1(2, 3);
Stone<int> r2(3, 3);
Stone<int> r3=compare(r1, r2);
cout<<"The weight of smaller stone is: "<<r3.myWeight()<<endl;
}知识点补充
size_t和size_type
- size_t 是cstddef头文件中定义的无符号整数类型,它的空间足够大,能够表示任意数组或向量的大小
- size_t 和 size_type的区别
The standard containers define size_type as a typedef to Allocator::size_type (Allocator is a template parameter), which for std::allocator
::size_type is typically defined to be size_t (or a compatible type). So for the standard case, they are the same. However, if you use a custom allocator a different underlying type could be used. So container::size_type is preferable for maximum generality.
成员访问运算符
a->b等价于(*a).b- 解引用运算符的优先级低于点运算符,因此在执行解引用运算的子表达式两端需要加上括号
#include<iostream>
#include<vector>
using namespace std;
int main(){
string s="a string", *p=&s;
auto n=s.size();
auto n1=(*p).size();
auto n2=p->size();
// 输出均为 8
cout<<n;
cout<<n1;
cout<<n2;
}- 智能指针
unique_ptr”独占”所指的对象
#include<iostream>
#include <memory>
using namespace std;
class Entity {
public:
Entity() {
cout << "Create Entity" << endl;
}
~Entity() {
cout << "Destroy Entity" << endl;
}
void print(){
cout << "Print Entity" << endl;
}
};
int main(){
// unique_ptr:以下两种方式均可
unique_ptr<Entity> ue= make_unique<Entity>();
// unique_ptr<Entity> ue(new Entity());
// 因为是独一份,所以不能这样操作:unique_ptr<Entity> ue1=ue;
ue->print();
}
// 结果:
// Create Entity
// Print Entity
// Destroy Entityshared_ptr允许多个指针指向同一个对象(可以用auto se0代替shared_ptr
se0)。每个shared_ptr都有一个关联的计数器,称其为引用计数,若计数器变为0,则自动释放自己管理的对象(通过析构函数完成销毁工作)
make_shared函数在动态内存中分配一个对象并初始化它,返回指向此对象的shared_ptr
#include<iostream>
#include <memory>
using namespace std;
class Entity {
public:
Entity() {
cout << "Create Entity" << endl;
}
~Entity() {
cout << "Destroy Entity" << endl;
}
void print(){
cout << "Print Entity" << endl;
}
};
int main(){
// shared_ptr:以下两种方式均可
shared_ptr<Entity> se0= make_shared<Entity>(); // auto se0= make_shared<Entity>();
// shared_ptr<Entity> se0(new Entity());
shared_ptr<Entity> se1=se0; // 因为是共享的,所以可以这样操作
se0->print();
// 结果:
// Create Entity
// Print Entity
// Destroy Entity
}weak_ptr是一种弱引用,指向shared_ptr所管理的对象
#include<iostream>
#include <memory>
using namespace std;
class Entity {
public:
Entity() {
cout << "Create Entity" << endl;
}
~Entity() {
cout << "Destroy Entity" << endl;
}
void print(){
cout << "Print Entity" << endl;
}
};
int main(){
// weak_ptr:是一种弱引用,指向shared_ptr所管理的对象
shared_ptr<Entity> se3= make_shared<Entity>();
weak_ptr<Entity> we=se3;
}
// 结果:
// Create Entity
// Destroy Entity
}- Functor
- for_each经常与functor配合使用
Functors are objects that can be treated as though they are a function or function pointer. It can be used with () in the manner of a function.
- for_each经常与functor配合使用
#include <iostream>
struct absValue
{
float operator()(float f) {
return f > 0 ? f : -f;
}
};
int main( )
{
using namespace std;
float f = -123.45;
absValue aObj;
float abs_f = aObj(f);
cout << "f = " << f << " abs_f = " << abs_f << endl;
return 0;
}#include <iostream>
#include <vector>
#include <initializer_list>
template<class T>
struct S {
std::vector<T> v;
S(std::initializer_list<T> l) : v(l) {
std::cout << "constructed with a " << l.size() << "-element list\n";
}
void append(std::initializer_list<T> l) {
v.insert(v.end(), l.begin(), l.end());
}
std::pair<const T *, std::size_t> c_arr() const {
return {&v[0], v.size()}; // copy list-initialization in return statement
// this is NOT a use of std::initializer_list
}
};
template<typename T>
void templated_fn(T) {}
int main() {
S<int> s = {1, 2, 3, 4, 5}; // copy list-initialization
s.append({6, 7, 8}); // list-initialization in function call
std::cout << "The vector size is now " << s.c_arr().second << " ints:\n";
for (auto n : s.v)
std::cout << n << ' ';
std::cout << '\n';
std::cout << "Range-for over brace-init-list: \n";
for (int x : {-1, -2, -3}) // the rule for auto makes this ranged-for work
std::cout << x << ' ';
std::cout << '\n';
auto al = {10, 11, 12}; // special rule for auto
std::cout << "The list bound to auto has size() = " << al.size() << '\n';
// templated_fn({1, 2, 3}); // compiler error! "{1, 2, 3}" is not an expression,
// it has no type, and so T cannot be deduced
templated_fn<std::initializer_list<int>>({1, 2, 3}); // OK
templated_fn<std::vector<int>>({1, 2, 3}); // also OK
}
//结果:
//constructed with a 5-element list
//The vector size is now 8 ints:
//1 2 3 4 5 6 7 8
//Range-for over brace-init-list:
//-1 -2 -3
//The list bound to auto has size() = 3
- 尾置类型转换 Trailing return type
- When a trailing return type is used, the placeholder return type must be auto.
// Trailing return type is used to represent
// a fully generic return type for a+b.
template <typename FirstType, typename SecondType>
auto add(FirstType a, SecondType b) -> decltype(a + b){
return a + b;
}
int main(){
// The first template argument is of the integer type, and
// the second template argument is of the character type.
add(1, 'A'); // 结果为66
// Both the template arguments are of the integer type.
add(3, 5); // 结果为8
}- 左值和右值 lvalue and rvalue,clear explanation!!!
- In C++ an lvalue is something that points to a specific memory location. On the other hand, a rvalue is something that doesn’t point anywhere. In general, rvalues are temporary and short lived, while lvalues live a longer life since they exist as variables. It’s also fun to think of lvalues as containers and rvalues as things contained in the containers. Without a container, they would expire.
- auto类型说明
- auto会忽略顶层const,同时保留底层cosnt (见C++Primer P61) 。auto 用于初始化时的类型推导,总是“值类型”,也可以加上修饰符产生新类型
- 顶层const:指针本身是一个常量,而指针指向的对象(这个内容可以变)。比如:我就喜欢坐在第一排中间,我就焊在这个座位上了。不管这个座位是木头椅子还是人体工学椅。对应的代码:
int * const pi=&i - 底层const:指针所指的对象是一个常量,而指针可以随意跳。比如:一开始我指向了一个木头椅子(木头椅子这个对象是不会变的),我想更舒服一些,那我就指向人体工学椅。对应的代码:
const int * pi=&ci
#include <memory>
#include <iostream>
using namespace std;
int main() {
int x = 1;
auto *a = &x;
cout << typeid(a).name() << endl; // a为int * 类型
const int y = 2;
auto e = y; // e为int类型 ,而不是const int 类型。可以对e重新赋值: e=3;
cout << typeid(e).name() << endl;
auto &c = x;
cout << typeid(c).name() << endl; // c为int & 类型
const auto f = y; // f为const int 类型。不可以对f重新赋值: f=4;
cout << typeid(f).name() << endl;
}
- sizeof 运算符
#include <memory>
#include <iostream>
using namespace std;
int main() {
char x[]="abc";
char y[]={'a','b','c'};
cout<<sizeof (x); // 4
cout<<sizeof (y);// 3
cout<<strlen(x); // 3
cout<<strlen(y); //3
cout << "Size of char : " << sizeof(char) << endl;
cout << "Size of int : " << sizeof(int) << endl;
cout << "Size of short int : " << sizeof(short int) << endl;
cout << "Size of long int : " << sizeof(long int) << endl;
cout << "Size of float : " << sizeof(float) << endl;
cout << "Size of double : " << sizeof(double) << endl;
cout << "Size of wchar_t : " << sizeof(wchar_t) << endl;
}
//Size of int : 4
//Size of short int : 2
//Size of long int : 8
//Size of float : 4
//Size of double : 8
//Size of wchar_t : 4signed char and unsigned char both represent 1byte, but they have different ranges.
| Type | range |
|---|---|
| signed char | -128 to +127 |
| unsigned char | 0 to 255 |
In signed char if we consider char letter = ‘A’, ‘A’ is represent binary of 65 in ASCII/Unicode, If 65 can be stored, -65 also can be stored. There are no negative binary values in ASCII/Unicode there for no need to worry about negative values.
- char 默认都是有符号的
- char char1 =-1,结果为-1;
- unsigned char char1 = -1,结果为255;
- unsigned char char1 = -2,结果为254
#include <stdio.h>
int main()
{
signed char char1 = 255;
unsigned char char3 = 255;
signed char char2 = -128;
unsigned char char4 = -128;
printf("Signed char(255) : %d\n",char1); // -1 超出-128到127的范围,结果为-1
printf("Unsigned char(255) : %d\n",char3); // 255 在0-255范围内,结果为255
printf("\nSigned char(-128) : %d\n",char2); //-128 在-128到127的范围,结果为-128
printf("Unsigned char(-128) : %d\n",char4); //128 无符号的-128相当于128,结果为128
return 0;
}
- memset, memset_s
1) void *memset( void *dest, int ch, size_t count ); : A copy of dest
2) errno_t memset_s( void *dest, rsize_t destsz, int ch, rsize_t count );:zero on success, non-zero on error. Also on error, if dest is not a null pointer and destsz is valid, writes destsz fill bytes ch to the destination array. (如果成功,则返回0.否则返回非0)
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
int main(void)
{
char str[] = "ghghghghghghghghghghgh";
puts(str);
memset(str,'a',5); // 把string的前5个元素赋值为a
puts(str);
int r = memset_s(str, sizeof str, 'b', 5); // 把string的前5个元素赋值为a
printf("str = \"%s\", r = %d\n", str, r); // 成功了,返回0
r = memset_s(str, 5, 'c', 10); // count is greater than destsz
printf("str = \"%s\", r = %d\n", str, r); // 只需要5个,但给了10个。返回的r非0。str的前5个元素改变了
r = memset_s(str, 5, 'd', 2); // count is less than destsz
printf("str = \"%s\", r = %d\n", str, r); // 需要5个,但只给了2个。那就只改变前2个,r为0。仍然成功返回
}
//ghghghghghghghghghghgh
//aaaaahghghghghghghghgh
//str = "bbbbbhghghghghghghghgh", r = 0
//str = "ccccchghghghghghghghgh", r = 84
//str = "ddccchghghghghghghghgh", r = 0



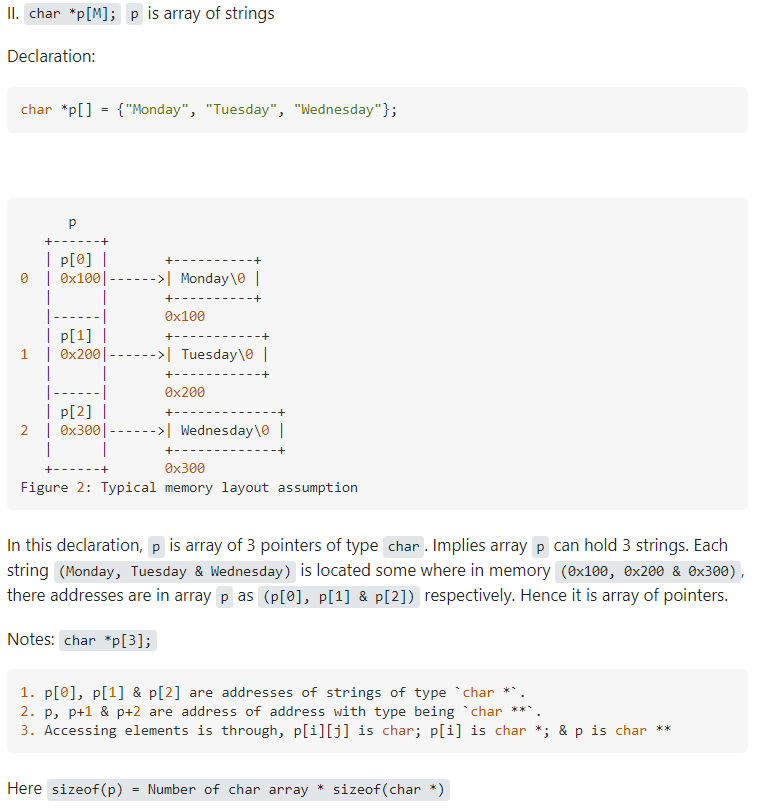
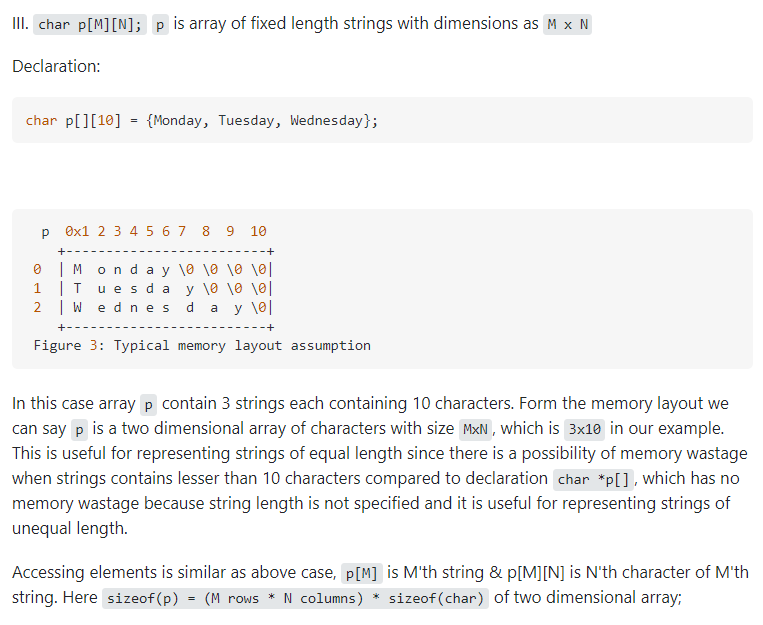
- 指针数组 数组指针 指针函数 函数指针
int *p[4];//指针数组。 是个有4个元素的数组, 每个元素是指向整型的指针 。(数组的每个元素都是指针)[]的优先级比*高, 所以int p[4]中,p先与[]结合,表示这是一个存放四个元素的数组,然后再与 int 结合,表示数组里存放的是指针
int (*p)[4];//数组指针。 它是一个指针,指向有4个整型元素的数组。 (一个指针指向有4个整型元素的数组)int *func(void);//指针函数。 无参函数, 返回整型指针。 (函数的返回值为int*)int (*func)(void);//表示函数指针,可以指向无参, 且返回值为整型指针的函数。 (函数的返回值为int)
- Difference between char *p,char p[],char p[][]
- 在64位系统中,一个指针占8个字节

#include <iostream>
#include <string>
#include <algorithm>
using namespace std;
void helper(string & a){
a+="!";
// return a;
}
void helper1(string a){
a+="+++";
}
int main ()
{
char a = 'g';
char *b = &a;
// 指向char指针的指针
char **p = &b;
cout<<sizeof (p)<<endl; // 8 在64位系统中,一个指针占8个字节
// 这是一个数组,数组中存放的是指针
char *p1[] = {"Monday", "Tuesday", "Wednesday"}; // char *p1[]就是char *p1[3]
cout<<sizeof (p1)<<endl; // 3*8 数组中有3个元素,每个元素都是一个指针(占8个字节),所以是3*8
// 这是一个二维数组
char p2[][10] = {"Monday", "Tuesday", "Wednesday"};
cout<<sizeof (p2)<<endl; // 3*10
}用虚继承的方式避免菱形继承。先构造父类,再构造子类,(同级)构造函数的调用只与继承的顺序有关
#include<iostream>
using namespace std;
class A{
public:
A(char *s)
{
cout<<s<<endl;
}
~A(){}
};
class B:virtual public A
{
public:
B(char *s1,char*s2):A(s1){
cout<<s2<<endl;
}
};
class C:virtual public A
{
public:
C(char *s1,char*s2):A(s1){
cout<<s2<<endl;
}
};
class D:public C,public B
{
public:
D(char *s1,char *s2,char *s3,char *s4):B(s1,s2),C(s1,s3),A(s1)
{
cout<<s4<<endl;
}
};
int main() {
D *p=new D("class A","class B","class C","class D");
delete p;
return 0;
}
//class A
//class C
//class B
//class D- 浅拷贝和深拷贝
浅拷贝只是拷贝值,并不重新分配内存;深拷贝可以重新分配内存.
默认构造函数:不开辟堆空间,仅仅是分配一个栈内存,它可以由编译器自动创建和销毁.
自定义构造函数:完全可以替代默认构造函数,并且可以开辟动态内存,申请堆空间,后期必须显示地调用析构函数销毁.
如果类中有指针,若不写拷贝构造函数,则是浅拷贝,指针会指向同一块内存空间: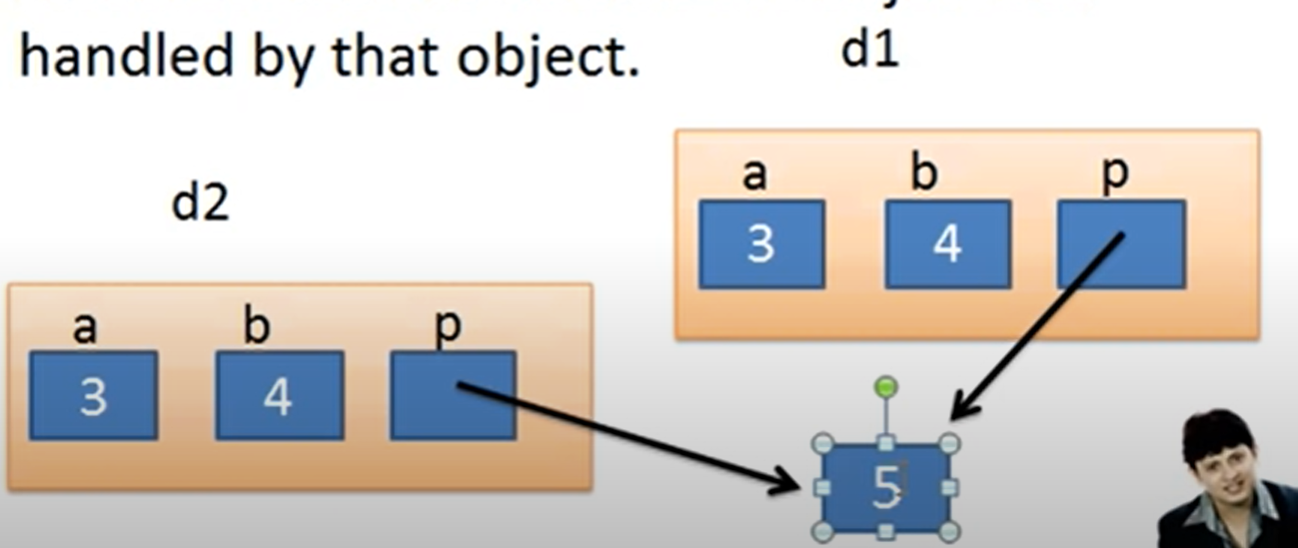
自己写了拷贝构造函数后,则是深拷贝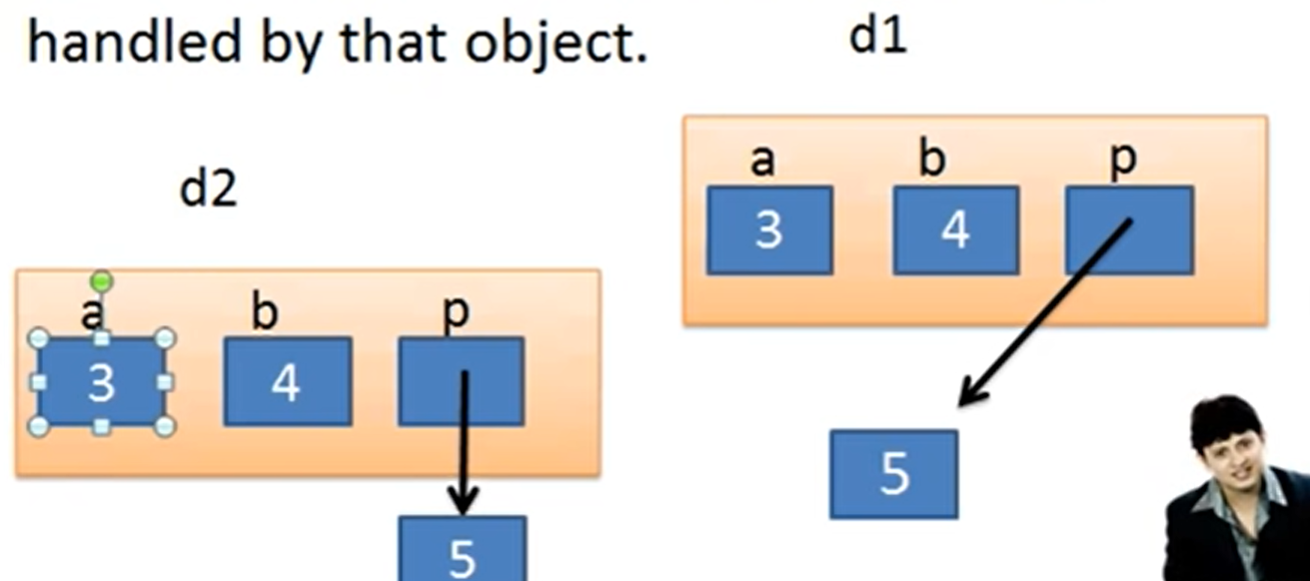
#include <iostream>
using namespace std;
class Base {
private:
int v;
int *p;
public:
// 带有指针时,因为在copy对象时需要重新分配空间,所以要自己写构造函数
// 无参构造函数
Base() : v(100), p(new int(100)) {
}
// 有参构造函数
Base(int val, int *ptr) : v(val), p(ptr) {
}
// 因为带有指针,所以需要deep copy 。 如果把这个拷贝构造函数注释掉,则b2的p的改变会影响b1的p
Base(const Base &rhs) {
v = rhs.v;
p = new int(*rhs.p);
// 或者
// p = new int;
// *p = *rhs.p;
}
~ Base() {
cout << "调用析构函数" << endl;
}
int getV() const {
return v;
}
void setV(int val) {
v = val;
}
int getP() const {
return *p;
}
void setP(int ptr) {
*p = ptr;
}
};
int main() {
Base b1; // 调用无参构造函数
cout << "b1.getV(): " << b1.getV() << endl;
cout << "b1.getP(): " << b1.getP() << endl;
b1.setV(1);
b1.setP(2);
cout << "b1.getV(): " << b1.getV() << endl;
cout << "b1.getP(): " << b1.getP() << endl;
Base b2 = b1; // 等于号也相当于是拷贝。 也可以 Base b2(b1); 因为写了拷贝构造函数,所以可以实现深拷贝
b2.setV(3);
b2.setP(4);
cout << "b1.getV(): " << b1.getV() << endl;
cout << "b1.getP(): " << b1.getP() << endl; // 因为是深拷贝,所以b2的p的改变没有影响到b1的p
cout << "b2.getV(): " << b2.getV() << endl;
cout << "b2.getP(): " << b2.getP() << endl;
// 调用有参构造函数
Base b3(6, new int(7));
cout << "b3.getV(): " << b3.getV() << endl;
cout << "b3.getP(): " << b3.getP() << endl;
}
//b1.getV(): 100
//b1.getP(): 100
//b1.getV(): 1
//b1.getP(): 2
//b1.getV(): 1
//b1.getP(): 2
//b2.getV(): 3
//b2.getP(): 4
//b3.getV(): 6
//b3.getP(): 7
//调用析构函数
//调用析构函数
//调用析构函数如果是单线程,则相当于一个人在工作。找完奇数后找偶数
如果是多线程,则相当于多个人在工作(本例中是两个人)。奇数偶数一起找

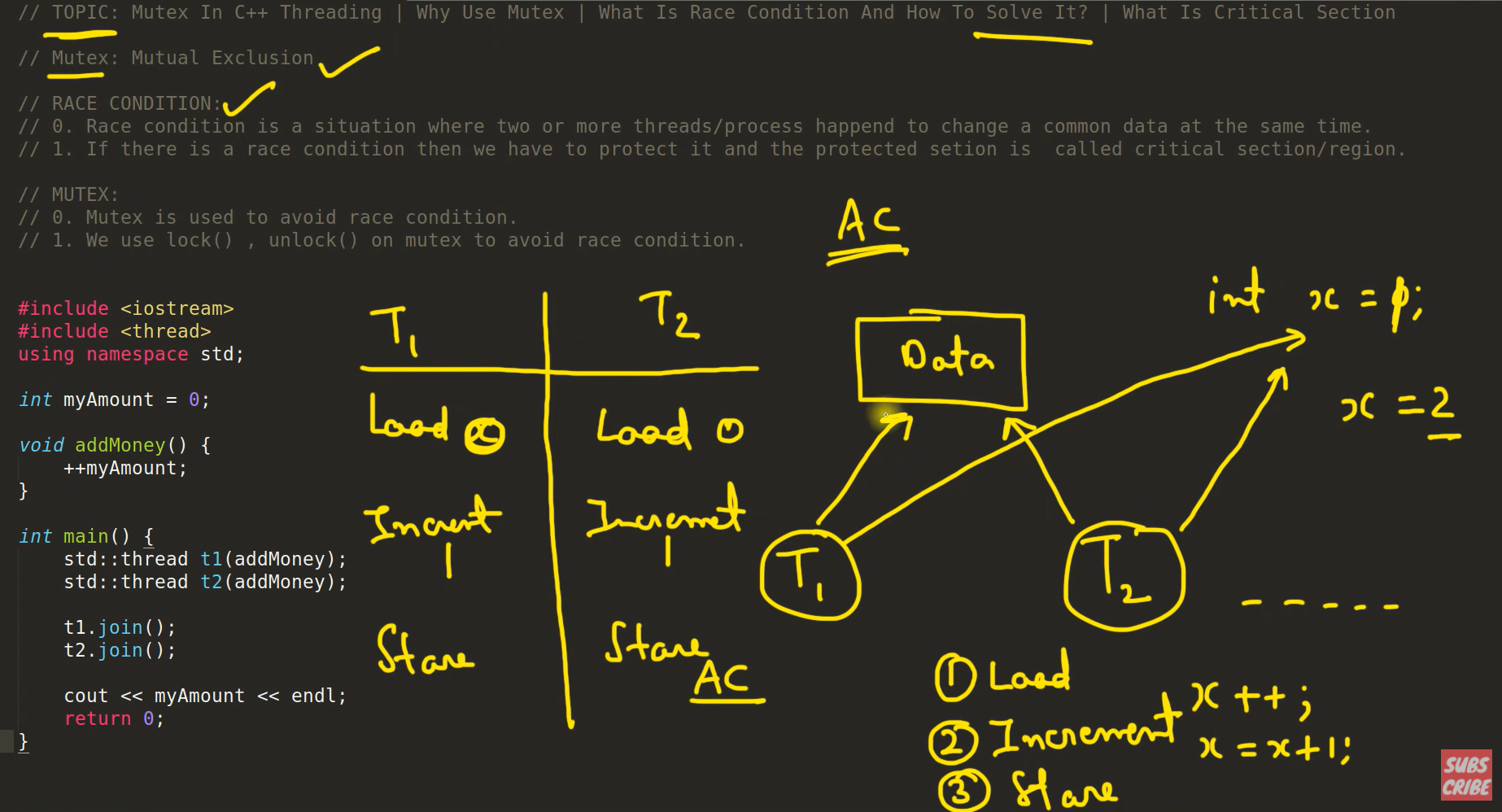
load -> increment -> store
加载数据 -> 更新数据 (如增加1) -> 存储(已更新的)数据
-
- 函数不能返回指向栈内存的指针,因为返回的都是值拷贝
早在 C++03 里,聚合类型(aggregate types)就已经可以被列表初始化了,比如数组和不自带构造函数的结构体:
#include <iostream>
using namespace std;
typedef struct {
int age;
string name;
}Person;
int main() {
Person p{10, "Amy"};
cout<<p.age<<endl;
cout<<p.name<<endl;
}C++11 中,该特性得到进一步的推广,任何对象类型都可以被列表初始化。示范如下:
// Vector 接收了一个初始化列表。
vector<string> v{"foo", "bar"};
// 不考虑细节上的微妙差别,大致上相同。
// 您可以任选其一。
vector<string> v = {"foo", "bar"};
// 可以配合 new 一起用。
auto p = new vector<string>{"foo", "bar"};
// map 接收了一些 pair, 列表初始化大显神威。
map<int, string> m = {{1, "one"}, {2, "2"}};
// 初始化列表也可以用在返回类型上的隐式转换。
vector<int> test_function() { return {1, 2, 3}; }
// 初始化列表可迭代。
for (int i : {-1, -2, -3}) {}
// 在函数调用里用列表初始化。
void TestFunction2(vector<int> v) {}
TestFunction2({1, 2, 3});列表初始化也适用于常规数据类型的构造,哪怕没有接收 std::initializer_list
class MyOtherType {
public:
explicit MyOtherType(string);
MyOtherType(int, string);
};
MyOtherType m = {1, "b"};
// 不过如果构造函数是显式的(explict),您就不能用 `= {}` 了。
MyOtherType m{"b"};- 在类中使用结构体
类的一个成员变量是结构体,在构造函数中,可以初始化该结构体
#include <iostream>
using namespace std;
typedef struct{
int age;
string name;
}Stu;
Stu stu1{stu1.age=10,
stu1.name="Amy"};
class Base{
public:
Stu stu_base_;
int score_;
Base(Stu temp,int score):stu_base_(temp),score_(score){
cout<<"stu_base_.age: "<<stu_base_.age<<endl;
cout<<"stu_base_.name: "<<stu_base_.name<<endl;
cout<<"score_: "<<score_<<endl;
};
};
int main()
{
Base b(stu1,100);
}
// stu_base_.age: 10
// stu_base_.name: Amy
// score_: 100或者也可以用函数来初始化类中的结构体
#include <iostream>
using namespace std;
typedef struct{
int age;
string name;
}Stu;
//Stu stu1{stu1.age=10,
// stu1.name="Amy"};
class Base{
public:
Stu s1;
Stu assign(){
Stu s2;
// s2=stu1; // 也可以直接用外面的stu1
s2.age=11;
s2.name="Bob";
return s2;
}
Base():s1(assign()){};
};
int main(){
Base bb= Base();
cout<<bb.s1.age<<endl; //11
}- C++中
string、char *、char[]、const char*的转换
bool mkpath( std::string path )
{
bool bSuccess = false;
int nRC = ::mkdir( path.c_str(), 0775 );
if( nRC == -1 )
{
switch( errno )
{
case ENOENT:
//parent didn't exist, try to create it
if( mkpath( path.substr(0, path.find_last_of('/')) ) )
//Now, try to create again.
bSuccess = 0 == ::mkdir( path.c_str(), 0775 );
else
bSuccess = false;
break;
case EEXIST:
//Done!
bSuccess = true;
break;
default:
bSuccess = false;
break;
}
}
else
bSuccess = true;
return bSuccess;
}- 函数中局部变量的返回
- 函数不能返回指向栈内存的指针,因为函数返回的都是值拷贝
- Can a local variable’s memory be accessed outside its scope?
- (类比的示例很好)C++ is not a safe language. It will cheerfully allow you to break the rules of the system. If you try to do something illegal and foolish like going back into a room you’re not authorized to be in and rummaging through a desk that might not even be there anymore, C++ is not going to stop you. Safer languages than C++ solve this problem by restricting your power – by having much stricter control over keys, for example.
- typename



