创建型模式
创建型模式提供创建对象的机制, 增加已有代码的灵活性和可复用性。
简单工厂模式
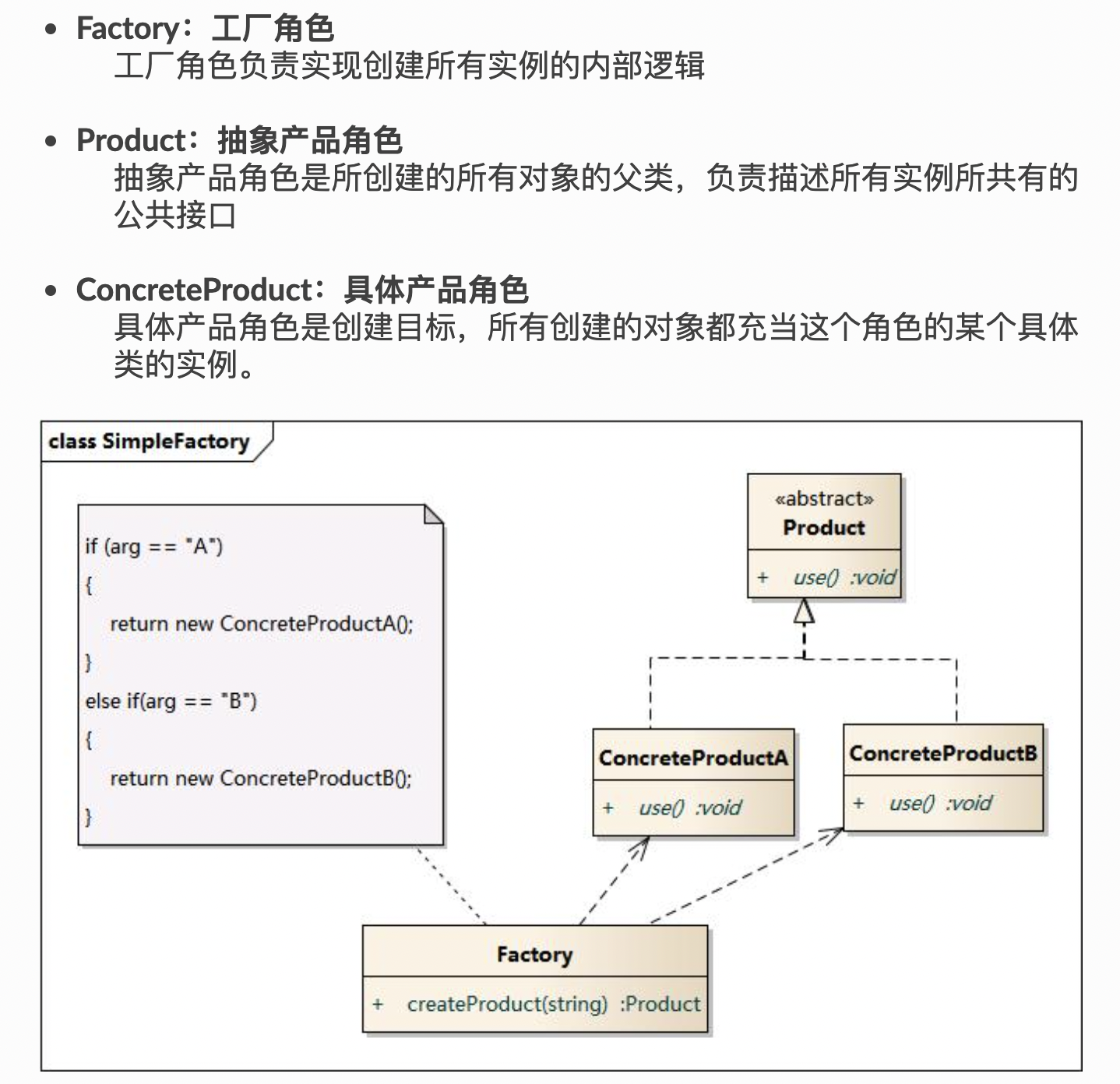
工厂类含有必要的判断逻辑,可以决定在什么时候创建哪一个产品类的实例,客户端可以免除直接创建产品对象的责任,而仅仅“消费”产品;简单工厂模式通过这种做法实现了对责任的分割,它提供了专门的工厂类用于创建对象。
简单工厂模式最大的优点在于实现对象的创建和对象的使用分离,将对象的创建交给专门的工厂类负责
工厂方法模式
工厂方法解决了在不指定具体类的情况下创建产品对象的问题。如果你希望用户能扩展你软件库或框架的内部组件, 可使用工厂方法
假设你使用开源 UI 框架编写自己的应用。 你希望在应用中使用圆形按钮, 但是原框架仅支持矩形按钮。 你可以使用 圆形按钮RoundButton子类来继承标准的 按钮Button类。 但是, 你需要告诉 UI框架UIFramework类使用新的子类按钮代替默认按钮。
为了实现这个功能, 你可以根据基础框架类开发子类 圆形按钮 UIUIWithRoundButtons , 并且重写其 createButton创建按钮方法。 基类中的该方法返回 按钮对象, 而你开发的子类返回 圆形按钮对象。 现在, 你就可以使用 圆形按钮 UI类代替 UI框架类
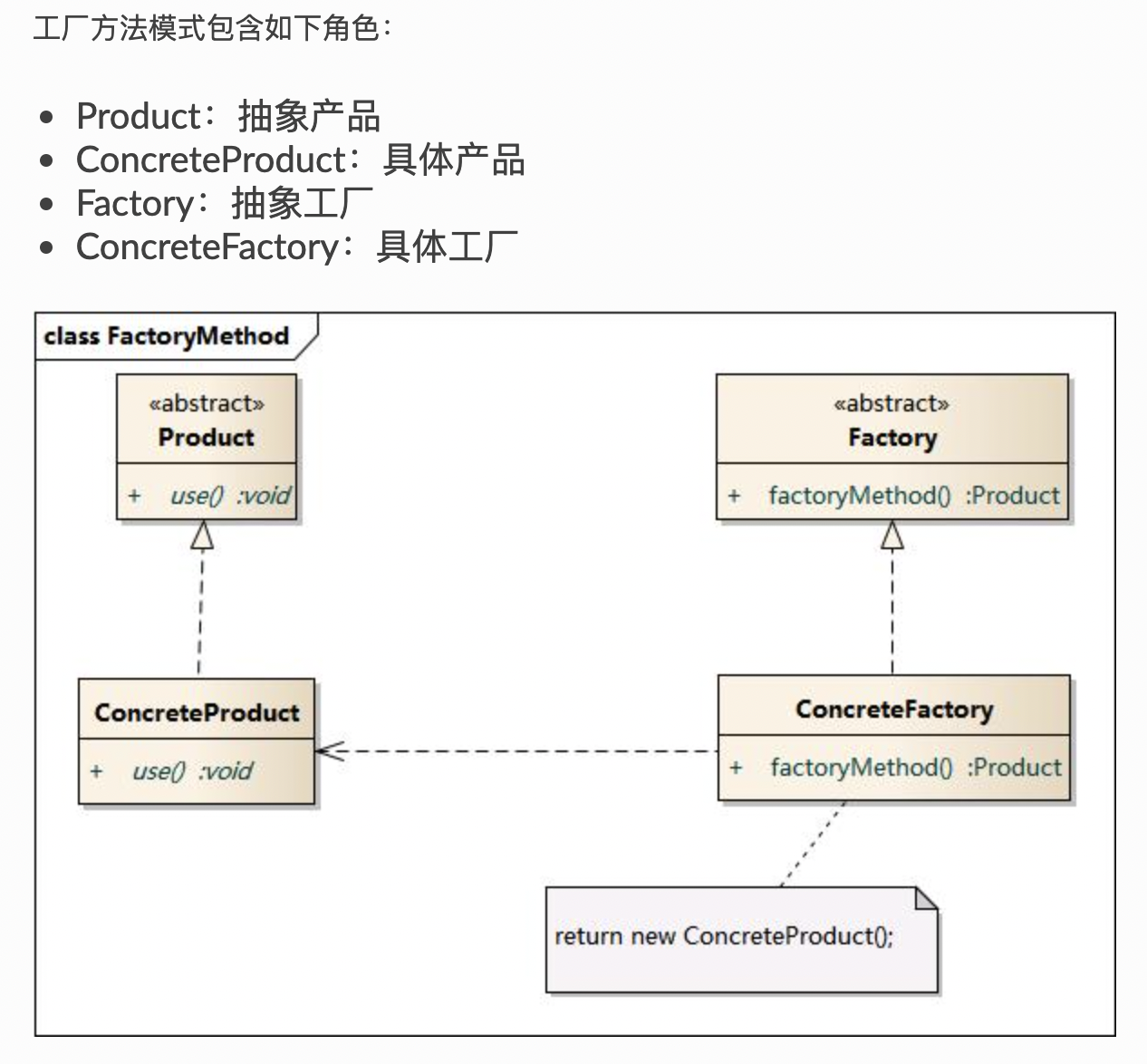
在工厂方法模式中,工厂父类负责定义创建产品对象的公共接口,而工厂子类则负责生成具体的产品对象,这样做的目的是将产品类的实例化操作延迟到工厂子类中完成,即通过工厂子类来确定究竟应该实例化哪一个具体产品类。
在工厂方法模式中,核心的工厂类不再负责所有产品的创建,而是将具体创建工作交给子类去做。这个核心类仅仅负责给出具体工厂必须实现的接口,而不负责哪一个产品类被实例化这种细节,这使得工厂方法模式可以允许系统在不修改工厂角色的情况下引进新产品
客户端代码仅通过其抽象接口与工厂和产品进行交互。 该接口允许同一客户端代码与不同产品进行交互。 你只需创建一个具体工厂类并将其传递给客户端代码即可
抽象工厂模式
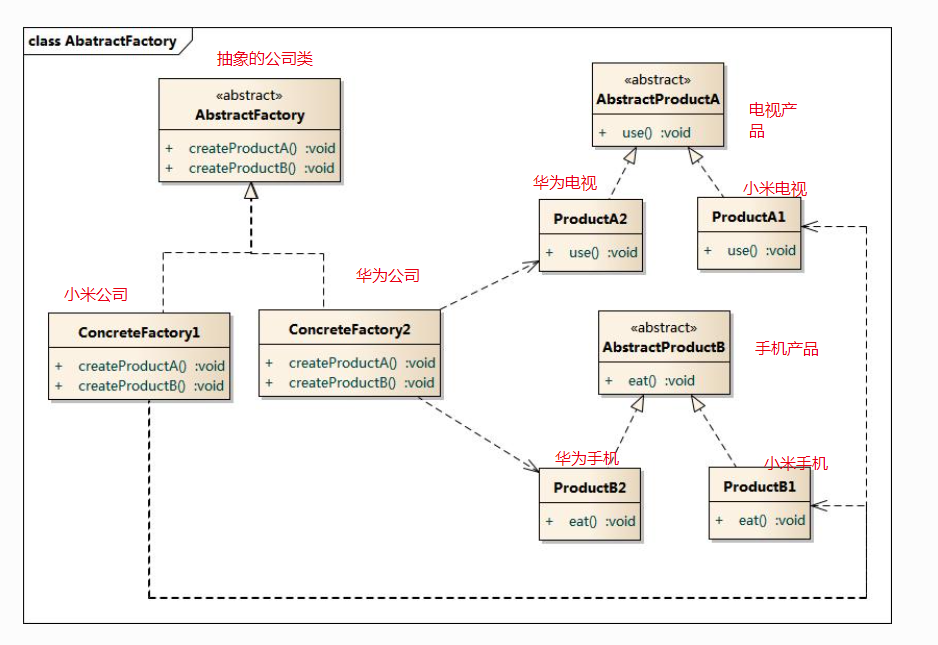
当系统所提供的工厂所需生产的具体产品并不是一个简单的对象,而是多个位于不同产品等级结构中属于不同类型的具体产品时(比如一个公司既生产电视,又生产手机,手表等产品)需要使用抽象工厂模式。
抽象工厂模式包含四个角色:
- 抽象工厂用于声明生成抽象产品的方法;
- 具体工厂实现了抽象工厂声明的生成抽象产品的方法,生成一组具体产品,这些产品构成了一个产品族,每一个产品都位于某个产品等级结构中;
- 抽象产品为每种产品声明接口,在抽象产品中定义了产品的抽象业务方法;
- 具体产品定义具体工厂生产的具体产品对象,实现抽象产品接口中定义的业务方法。
#include <bits/stdc++.h>
using namespace std;
/**
* Each distinct product of a product family should have a base interface. All
* variants of the product must implement this interface.
*/
// 电视类
class AbstractProductA {
public:
virtual ~AbstractProductA() {};
virtual std::string UsefulFunctionA() const = 0;
};
/**
* Concrete Products are created by corresponding Concrete Factories.
*/
// 华为电视类
class ConcreteProductA1 : public AbstractProductA {
public:
std::string UsefulFunctionA() const override {
return "The result of the product A1.";
}
};
//小米电视类
class ConcreteProductA2 : public AbstractProductA {
std::string UsefulFunctionA() const override {
return "The result of the product A2.";
}
};
/**
* Here's the the base interface of another product. All products can interact
* with each other, but proper interaction is possible only between products of
* the same concrete variant.
*/
// 手机类
class AbstractProductB {
/**
* Product B is able to do its own thing...
*/
public:
virtual ~AbstractProductB() {};
virtual std::string UsefulFunctionB() const = 0;
/**
* ...but it also can collaborate with the ProductA.
*
* The Abstract Factory makes sure that all products it creates are of the
* same variant and thus, compatible.
*/
// 这个函数可以类比为:函数参数是一个电视类,可以用手机来操控电视
virtual std::string AnotherUsefulFunctionB(const AbstractProductA &collaborator) const = 0;
};
/**
* Concrete Products are created by corresponding Concrete Factories.
*/
// 华为手机类
class ConcreteProductB1 : public AbstractProductB {
public:
std::string UsefulFunctionB() const override {
return "The result of the product B1.";
}
/**
* The variant, Product B1, is only able to work correctly with the variant,
* Product A1. Nevertheless, it accepts any instance of AbstractProductA as an
* argument.
*/
// 用华为手机操控电视
std::string AnotherUsefulFunctionB(const AbstractProductA &collaborator) const override {
const std::string result = collaborator.UsefulFunctionA();
return "The result of the B1 collaborating with ( " + result + " )";
}
};
//小米手机类
class ConcreteProductB2 : public AbstractProductB {
public:
std::string UsefulFunctionB() const override {
return "The result of the product B2.";
}
/**
* The variant, Product B2, is only able to work correctly with the variant,
* Product A2. Nevertheless, it accepts any instance of AbstractProductA as an
* argument.
*/
// 用小米手机操控电视
std::string AnotherUsefulFunctionB(const AbstractProductA &collaborator) const override {
const std::string result = collaborator.UsefulFunctionA();
return "The result of the B2 collaborating with ( " + result + " )";
}
};
/**
* The Abstract Factory interface declares a set of methods that return
* different abstract products. These products are called a family and are
* related by a high-level theme or concept. Products of one family are usually
* able to collaborate among themselves. A family of products may have several
* variants, but the products of one variant are incompatible with products of
* another.
*/
// 抽象的工厂类。比如这个公司既生产电视,又生产手机
class AbstractFactory {
public:
virtual AbstractProductA *CreateProductA() const = 0;
virtual AbstractProductB *CreateProductB() const = 0;
};
/**
* Concrete Factories produce a family of products that belong to a single
* variant. The factory guarantees that resulting products are compatible. Note
* that signatures of the Concrete Factory's methods return an abstract product,
* while inside the method a concrete product is instantiated.
*/
// 华为公司类,这个类用于构建对应的电视对象和手机对象
class ConcreteFactory1 : public AbstractFactory {
public:
AbstractProductA *CreateProductA() const override {
return new ConcreteProductA1(); // 构建华为电视对象
}
AbstractProductB *CreateProductB() const override {
return new ConcreteProductB1(); // 构建华为手机对象
}
};
/**
* Each Concrete Factory has a corresponding product variant.
*/
// 小米公司类,这个类用于构建对应的电视对象和手机对象
class ConcreteFactory2 : public AbstractFactory {
public:
AbstractProductA *CreateProductA() const override {
return new ConcreteProductA2(); // 构建小米电视对象
}
AbstractProductB *CreateProductB() const override {
return new ConcreteProductB2(); // 构建小米手机对象
}
};
/**
* The client code works with factories and products only through abstract
* types: AbstractFactory and AbstractProduct. This lets you pass any factory or
* product subclass to the client code without breaking it.
*/
//客户端只需和抽象的电视类和手机类进行交互
void ClientCode(const AbstractFactory &factory) {
const AbstractProductA *product_a = factory.CreateProductA();
const AbstractProductB *product_b = factory.CreateProductB();
std::cout << product_b->UsefulFunctionB() << "\n";
std::cout << product_b->AnotherUsefulFunctionB(*product_a) << "\n";
delete product_a;
delete product_b;
}
int main() {
std::cout << "Client: Testing client code with the first factory type:\n";
ConcreteFactory1 *f1 = new ConcreteFactory1();
ClientCode(*f1); // 客户与华为的产品交互
delete f1;
std::cout << std::endl;
std::cout << "Client: Testing the same client code with the second factory type:\n";
ConcreteFactory2 *f2 = new ConcreteFactory2();
ClientCode(*f2); // 客户与小米的产品交互
delete f2;
return 0;
}
//Client: Testing client code with the first factory type:
//The result of the product B1.
//The result of the B1 collaborating with ( The result of the product A1. )
//
//Client: Testing the same client code with the second factory type:
//The result of the product B2.
//The result of the B2 collaborating with ( The result of the product A2. )
建造者模式(生成器模式)
无论是在现实世界中还是在软件系统中,都存在一些复杂的对象,它们拥有多个组成部分,如汽车,它包括车轮、方向盘、发送机等各种部件。而对于大多数用户而言,无须知道这些部件的装配细节,也几乎不会使用单独某个部件,而是使用一辆完整的汽车,可以通过建造者模式对其进行设计与描述,建造者模式可以将部件和其组装过程分开,一步一步创建一个复杂的对象。用户只需要指定复杂对象的类型就可以得到该对象,而无须知道其内部的具体构造细节。
在软件开发中,也存在大量类似汽车一样的复杂对象,它们拥有一系列成员属性,这些成员属性中有些是引用类型的成员对象。而且在这些复杂对象中,还可能存在一些限制条件,如某些属性没有赋值则复杂对象不能作为一个完整的产品使用;有些属性的赋值必须按照某个顺序,一个属性没有赋值之前,另一个属性可能无法赋值等。
复杂对象相当于一辆有待建造的汽车,而对象的属性相当于汽车的部件,建造产品的过程就相当于组合部件的过程。由于组合部件的过程很复杂,因此,这些部件的组合过程往往被“外部化”到一个称作建造者的对象里,建造者返还给客户端的是一个已经建造完毕的完整产品对象,而用户无须关心该对象所包含的属性以及它们的组装方式,这就是建造者模式的模式动机。
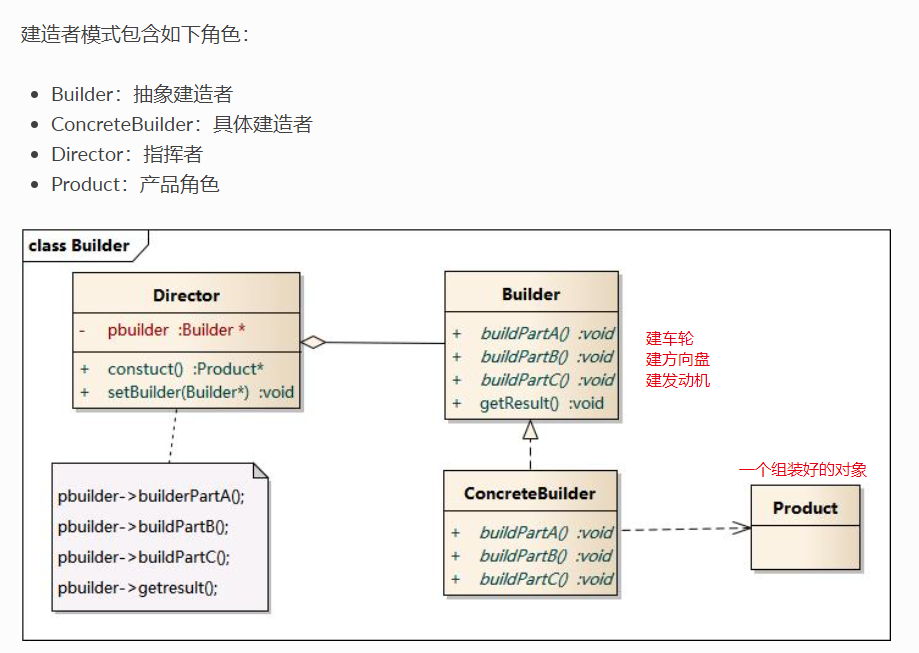
建造者模式的结构中还引入了一个指挥者类Director,该类的作用主要有两个:一方面它隔离了客户与生产过程;另一方面它负责控制产品的生成过程。指挥者针对抽象建造者编程,客户端只需要知道具体建造者的类型,即可通过指挥者类调用建造者的相关方法,返回一个完整的产品对象
在客户端代码中,无须关心产品对象的具体组装过程,只需确定具体建造者的类型即可,建造者模式将复杂对象的构建与对象的表现分离开来,这样使得同样的构建过程可以创建出不同的表现。
- 优点
- 在建造者模式中, 客户端不必知道产品内部组成的细节,将产品本身与产品的创建过程解耦,使得相同的创建过程可以创建不同的产品对象。
- 每一个具体建造者都相对独立,而与其他的具体建造者无关,因此可以很方便地替换具体建造者或增加新的具体建造者, 用户使用不同的具体建造者即可得到不同的产品对象 。
- 可以更加精细地控制产品的创建过程 。将复杂产品的创建步骤分解在不同的方法中,使得创建过程更加清晰,也更方便使用程序来控制创建过程。
- 增加新的具体建造者无须修改原有类库的代码,指挥者类针对抽象建造者类编程,系统扩展方便,符合“开闭原则”。
建造者模式包含如下四个角色:
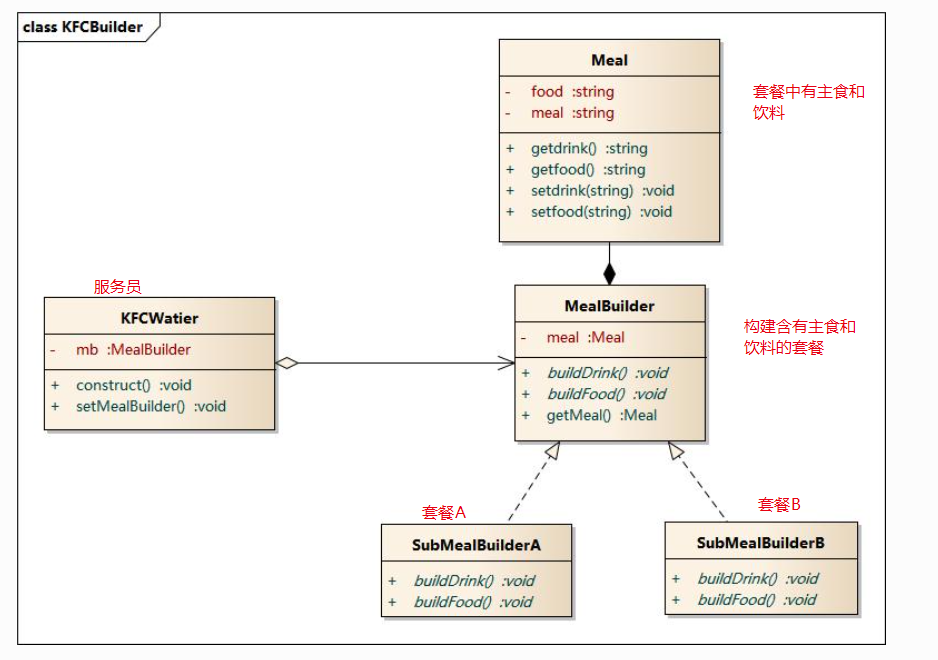
- 抽象建造者为创建一个产品对象的各个部件指定抽象接口;(要有主食,饮料,甜点等)
- 具体建造者实现了抽象建造者接口,实现各个部件的构造和装配方法,定义并明确它所创建的复杂对象,也可以提供一个方法返回创建好的复杂产品对象;(实现各个部件的构造和装配)
- 产品角色是被构建的复杂对象,包含多个组成部件;(建好的套餐)
- 指挥者负责安排复杂对象的建造次序,指挥者与抽象建造者之间存在关联关系,可以在其construct()建造方法中调用建造者对象的部件构造与装配方法,完成复杂对象的建造 (KFC服务员,用来指挥建造者如何构建套餐,比如汉堡配可乐,汉堡配可乐配冰淇淋,鸡肉卷配豆浆)
假设第一个建造者使用木头和玻璃制造房屋, 第二个建造者使用石头和钢铁, 而第三个建造者使用黄金和钻石。 在调用同一组步骤后, 第一个建造者会给你一栋普通房屋, 第二个会给你一座小城堡, 而第三个则会给你一座宫殿。 但是, 只有在调用构造步骤的客户端代码可以通过通用接口与建造者进行交互时, 这样的调用才能返回需要的房屋。
/**
* It makes sense to use the Builder pattern only when your products are quite
* complex and require extensive configuration.
*
* Unlike in other creational patterns, different concrete builders can produce
* unrelated products. In other words, results of various builders may not
* always follow the same interface.
*/
#include <vector>
#include <string>
#include <iostream>
using namespace std;
//具体的产品:建好的套餐,套餐中可能包含不同的parts(可能是各种主食和(或)饮料和(或)甜点的组合)
class Product1{
public:
std::vector<std::string> parts_;
// 展示套餐中包含的内容
void ListParts()const{
std::cout << "Product parts: ";
for (size_t i=0;i<parts_.size();i++){
if(parts_[i]== parts_.back()){
std::cout << parts_[i];
}else{
std::cout << parts_[i] << ", ";
}
}
std::cout << "\n\n";
}
};
/**
* The Builder interface specifies methods for creating the different parts of
* the Product objects.
*/
class Builder{
public:
virtual ~Builder(){}
virtual void ProducePartA() const =0; // 生产主食
virtual void ProducePartB() const =0;// 生产饮料
virtual void ProducePartC() const =0; // 生产甜点
};
/**
* The Concrete Builder classes follow the Builder interface and provide
* specific implementations of the building steps. Your program may have several
* variations of Builders, implemented differently.
*/
// 具体的建造者:实现各个部件的构造和装配
class ConcreteBuilder1 : public Builder{
private:
Product1* product;
/**
* A fresh builder instance should contain a blank product object, which is
* used in further assembly.
*/
public:
ConcreteBuilder1(){
this->Reset();
}
~ConcreteBuilder1(){
delete product;
}
void Reset(){
this->product= new Product1(); // 产生一个新的产品
}
/**
* All production steps work with the same product instance.
*/
void ProducePartA()const override{
this->product->parts_.push_back("PartA1"); // 套餐中放一个主食
}
void ProducePartB()const override{
this->product->parts_.push_back("PartB1"); // 套餐中放一个饮料
}
void ProducePartC()const override{
this->product->parts_.push_back("PartC1"); // 套餐中翻一个甜点
}
/**
* Concrete Builders are supposed to provide their own methods for
* retrieving results. That's because various types of builders may create
* entirely different products that don't follow the same interface.
* Therefore, such methods cannot be declared in the base Builder interface
* (at least in a statically typed programming language). Note that PHP is a
* dynamically typed language and this method CAN be in the base interface.
* However, we won't declare it there for the sake of clarity.
*
* Usually, after returning the end result to the client, a builder instance
* is expected to be ready to start producing another product. That's why
* it's a usual practice to call the reset method at the end of the
* `getProduct` method body. However, this behavior is not mandatory, and
* you can make your builders wait for an explicit reset call from the
* client code before disposing of the previous result.
*/
/**
* Please be careful here with the memory ownership. Once you call
* GetProduct the user of this function is responsable to release this
* memory. Here could be a better option to use smart pointers to avoid
* memory leaks
*/
Product1* GetProduct() {
Product1* result= this->product;
this->Reset();
return result;
}
};
/**
* The Director is only responsible for executing the building steps in a
* particular sequence. It is helpful when producing products according to a
* specific order or configuration. Strictly speaking, the Director class is
* optional, since the client can control builders directly.
*/
// 服务员的角色:负责告诉建造者怎么组装套餐,是只有主食,还是既有主食又有饮料
class Director{
/**
* @var Builder
*/
private:
Builder* builder;
/**
* The Director works with any builder instance that the client code passes
* to it. This way, the client code may alter the final type of the newly
* assembled product.
*/
public:
void set_builder(Builder* builder){
this->builder=builder;
}
/**
* The Director can construct several product variations using the same
* building steps.
*/
void BuildMinimalViableProduct(){ // 套餐中只有主食
this->builder->ProducePartA();
}
void BuildFullFeaturedProduct(){ // 套餐中都有
this->builder->ProducePartA();
this->builder->ProducePartB();
this->builder->ProducePartC();
}
};
/**
* The client code creates a builder object, passes it to the director and then
* initiates the construction process. The end result is retrieved from the
* builder object.
*/
/**
* I used raw pointers for simplicity however you may prefer to use smart
* pointers here
*/
// 客户只需要和服务员进行交互
void ClientCode(Director& director)
{
ConcreteBuilder1* builder = new ConcreteBuilder1();
director.set_builder(builder);
std::cout << "Standard basic product:\n";
director.BuildMinimalViableProduct();
Product1* p= builder->GetProduct();
p->ListParts();
delete p;
std::cout << "Standard full featured product:\n";
director.BuildFullFeaturedProduct();
p= builder->GetProduct();
p->ListParts();
delete p;
// Remember, the Builder pattern can be used without a Director class.
// 不用服务员的话,也可以自行组装套餐
std::cout << "Custom product:\n";
builder->ProducePartA();
builder->ProducePartC();
p=builder->GetProduct();
p->ListParts();
delete p;
delete builder;
}
int main(){
Director* director= new Director();
ClientCode(*director);
delete director;
return 0;
}
单例模式
对于系统中的某些类来说,只有一个实例很重要,例如,一个系统中可以存在多个打印任务,但是只能有一个正在工作的任务;一个系统只能有一个计时工具。
所以要让类自身负责保存它的唯一实例。这个类可以保证没有其他实例被创建,并且它可以提供一个访问该实例的方法。这就是单例模式的模式动机。
单例模式的要点有三个:一是某个类只能有一个实例;二是它必须自行创建这个实例;三是它必须自行向整个系统提供这个实例。
- 单例类拥有一个私有构造函数,确保用户无法通过new关键字直接实例化它。除此之外,该模式中包含一个静态私有成员变量与静态公有的工厂方法,该工厂方法负责检验实例的存在性并实例化自己,然后存储在静态成员变量中,以确保只有一个实例被创建
- 将默认构造函数设为私有, 防止其他对象使用单例类的new运算符。
- 新建一个静态构建方法作为构造函数。 该函数会 “偷偷” 调用私有构造函数来创建对象, 并将其保存在一个静态成员变量中。 此后所有对于该函数的调用都将返回这一缓存对象。
#include <iostream>
using namespace std;
class Singleton {
private:
int data_;
// 私有的静态成员变量:实例instance
static Singleton *instance;
// 私有的构造函数,确保只有类本身能够实例化它
Singleton(int data) : data_(data) {
}
// 赋值构造和拷贝构造函数都设为delete
Singleton(Singleton &other) = delete;
Singleton &operator=(Singleton &other) = delete;
public:
// 公有的静态方法,负责检查实例的存在及实例化自己
static Singleton *getInstance() {
if (!instance) {
instance = new Singleton(0);
}
return instance;
}
// 对实例的操作数据进行赋值及取值操作
int getData() const {
return data_;
}
void setData(int num) {
data_ = num;
}
};
//需要初始化静态成员变量
Singleton *Singleton::instance = 0;
int main() {
// 把实例赋值给s指针
Singleton *s = Singleton::getInstance();
cout << s->getData() << endl; // 初始数据为0
Singleton *s1 = Singleton::getInstance();
s1->setData(100);
cout << s1->getData() << endl; // s和s1都是同一个东西,赋值后数据为100
// s和s1相同,都在同一个地址中
std::cout << s << std::endl;
std::cout << s1 << std::endl;
}
// 0
// 100
// 0x1a1c20
// 0x1a1c20结构型模式
结构型模式(Structural Pattern)描述如何将类或者对象结合在一起形成更大的结构,就像搭积木,可以通过 简单积木的组合形成复杂的、功能更为强大的结构。
结构型模式可以分为类结构型模式和对象结构型模式
在系统中尽量使用关联关系来替代继 承关系,因此大部分结构型模式都是对象结构型模式
适配器模式
不同国家的插座是不同的,有国标,美标,英标等。适配器如同转换插座,让电器可以适用于各种国家的插座
- Target:一个玩具,默认输出一串正的字符串
- Adaptee:另外一个国家有一个叫Adaptee的玩具,它输出的字符串是反的
- Adapter是Target的子类:Adapter适配器类继承了Target类后,把Target类中的Request进行覆写,如果字符串是Adaptee玩具产生的,则对其进行翻转
- Adapter的构造函数为
(Adaptee *adaptee) : adaptee_(adaptee) {}, 用这种方式把adaptee指针对象传送给Adapter
- Adapter的构造函数为
- ClientCode函数:客户端只需要和Target类型的对象交互即可。
ClientCode(target):Target的Request函数正常输出正序字符串ClientCode(adapter):如果是Adaptee产生的字符串,因为用了adapter适配器,Target的Request函数同样正序输出
#include <vector>
#include <string>
#include <iostream>
#include <algorithm>
//using namespace std;
/**
* The Target defines the domain-specific interface used by the client code.
*/
//target:一个玩具,默认输出一串正的字符串
class Target {
public:
virtual ~Target() = default;
virtual std::string Request() const {
return "Target: The default target's behavior.";
}
};
/**
* The Adaptee contains some useful behavior, but its interface is incompatible
* with the existing client code. The Adaptee needs some adaptation before the
* client code can use it.
*/
// 另外一个国家有一个叫Adaptee的玩具,它输出的字符串是反的
class Adaptee {
public:
std::string SpecificRequest() const {
return ".eetpadA eht fo roivaheb laicepS";
}
};
/**
* The Adapter makes the Adaptee's interface compatible with the Target's
* interface.
*/
// Adapter适配器类继承了Target类后,把Target类中的Request进行覆写,如果字符串是Adaptee玩具产生的,则对其进行翻转
class Adapter : public Target {
private:
Adaptee *adaptee_;
public:
Adapter(Adaptee *adaptee) : adaptee_(adaptee) {}
std::string Request() const override { // 覆写Target类中的Request函数
std::string to_reverse = this->adaptee_->SpecificRequest();
std::reverse(to_reverse.begin(), to_reverse.end());
return "Adapter: (TRANSLATED) " + to_reverse;
}
};
/**
* The client code supports all classes that follow the Target interface.
*/
// 客户端只需要和正常的Target类进行交互即可。
void ClientCode(const Target *target) {
std::cout << target->Request();
}
int main() {
std::cout << "Client: I can work just fine with the Target objects:\n";
Target *target = new Target;
ClientCode(target);
std::cout << "\n\n";
Adaptee *adaptee = new Adaptee;
std::cout << "Client: The Adaptee class has a weird interface. See, I don't understand it:\n";
std::cout << "Adaptee: " << adaptee->SpecificRequest();
std::cout << "\n\n";
std::cout << "Client: But I can work with it via the Adapter:\n";
Adapter *adapter = new Adapter(adaptee);
ClientCode(adapter);
std::cout << "\n";
delete target;
delete adaptee;
delete adapter;
return 0;
}
//Client: I can work just fine with the Target objects:
//Target: The default target's behavior.
//
//Client: The Adaptee class has a weird interface. See, I don't understand it:
//Adaptee: .eetpadA eht fo roivaheb laicepS
//
// Client: But I can work with it via the Adapter:
//Adapter: (TRANSLATED) Special behavior of the Adaptee.
适配器也可以通过多重继承的方式,覆写Target的Request函数
// 通过多重继承,覆写Target的Request请求
class Adapter : public Target, public Adaptee {
public:
Adapter() {}
std::string Request() const override {
std::string to_reverse = SpecificRequest();
std::reverse(to_reverse.begin(), to_reverse.end());
return "Adapter: (TRANSLATED) " + to_reverse;
}
};桥接模式
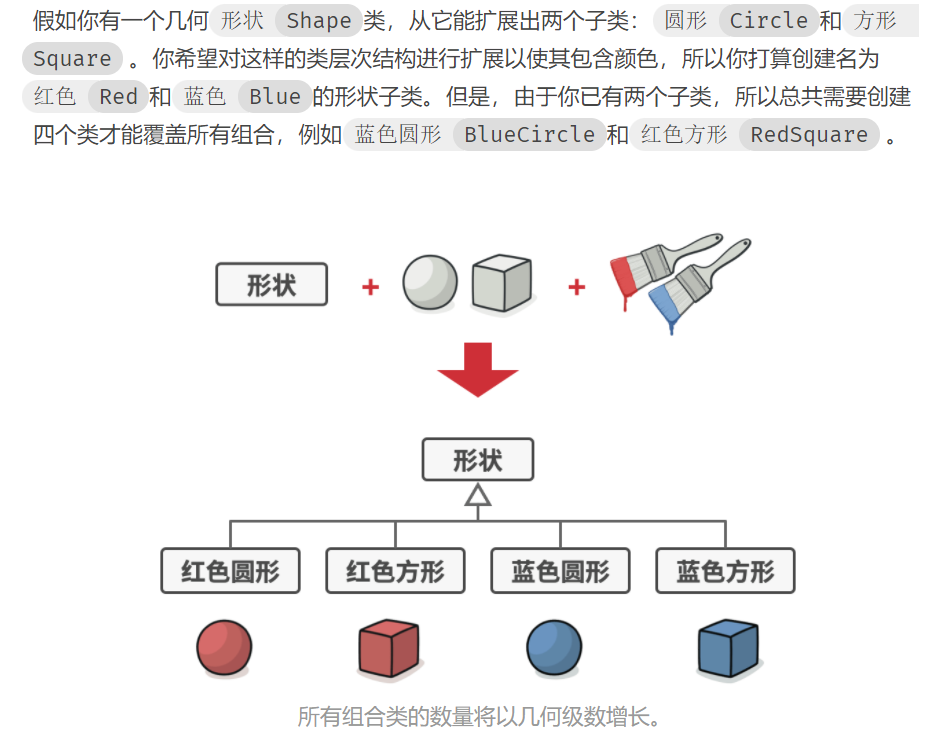
为了使组合类的数量不要增长太多,桥接模式通过将继承改为组合的方式来解决这个问题。 具体来说, 就是抽取其中一个维度并使之成为独立的类层次, 这样就可以在初始类中引用这个新层次的对象, 从而使得一个类不必拥有所有的状态和行为。
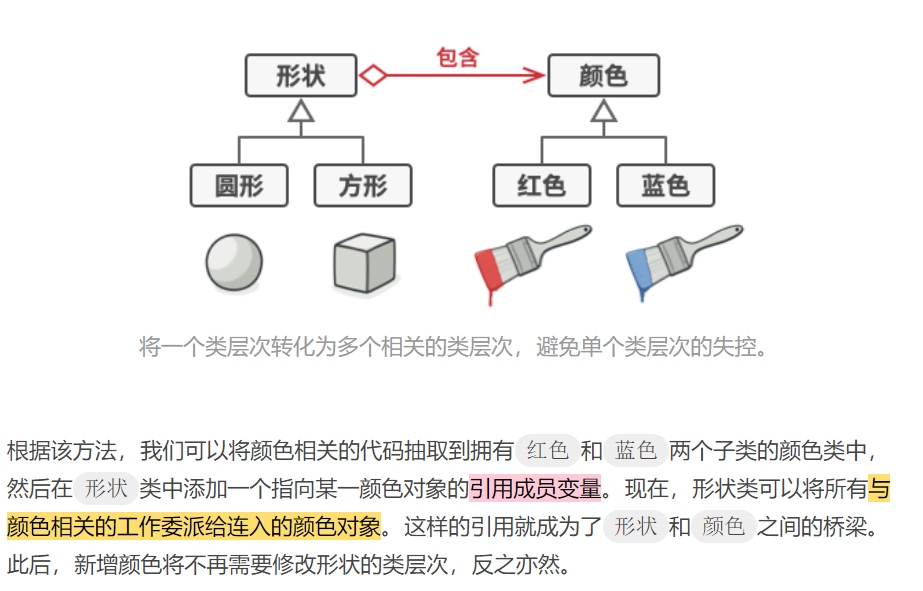
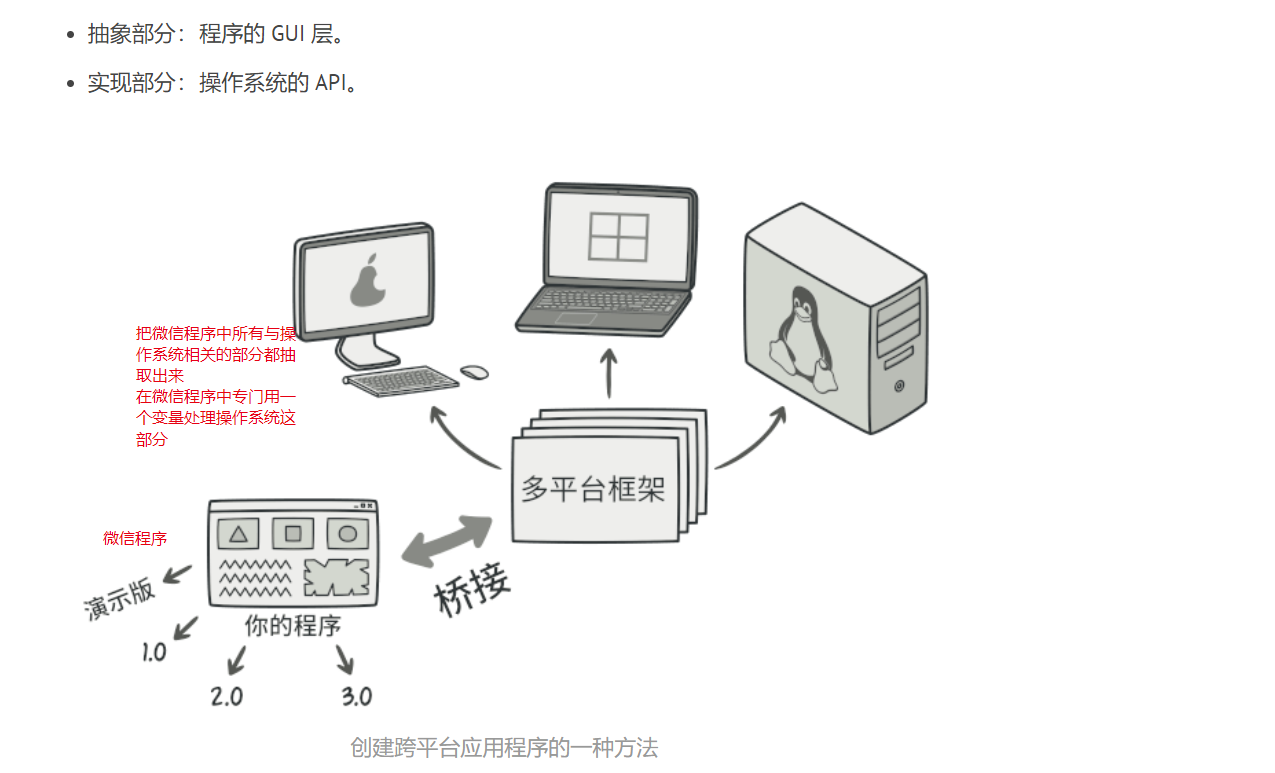
抽象对象控制程序的外观, 并将真实工作委派给连入的实现对象。 不同的实现只要遵循相同的接口就可以互换, 使同一 GUI 可在 Windows 和 Linux 下运行。
组合模式
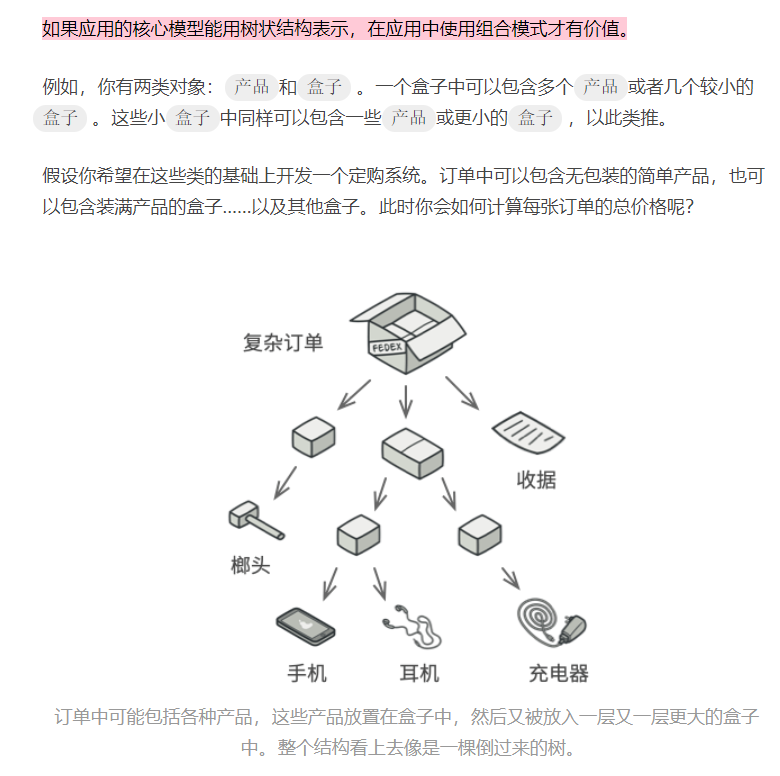
- 如果你需要实现树状对象结构, 可以使用组合模式。
- 组合模式为你提供了两种共享公共接口的基本元素类型: 简单叶节点和复杂容器。 容器中可以包含叶节点和其他容器。 这使得你可以构建树状嵌套递归对象结构。
- 如果你希望客户端代码以相同方式处理简单和复杂元素, 可以使用该模式。
- 组合模式中定义的所有元素共用同一个接口。 在这一接口的帮助下, 客户端不必在意其所使用的对象的具体类。
装饰模式
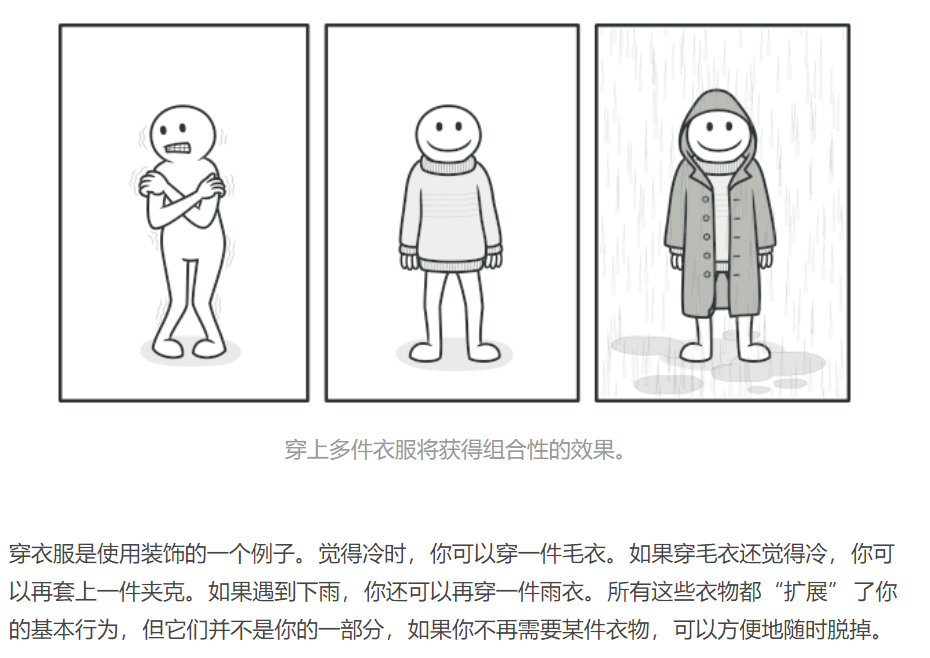

与继承关系相比,关联关系的主要优势在于不会破坏类的封装性,而且继承是一种耦合度较大的静态关系,无法在程序运行时动态扩展。在软件开发阶段,关联关系虽然不会比继承关系减少编码量,但是到了软件维护阶段,由于关联关系使系统具有较好的松耦合性,因此使得系统更加容易维护。当然,关联关系的缺点是比继承关系要创建更多的对象。
使用装饰模式来实现扩展比继承更加灵活,它以对客户透明的方式动态地给一个对象附加更多的责任。装饰模式可以在不需要创造更多子类的情况下,将对象的功能加以扩展。
外观模式
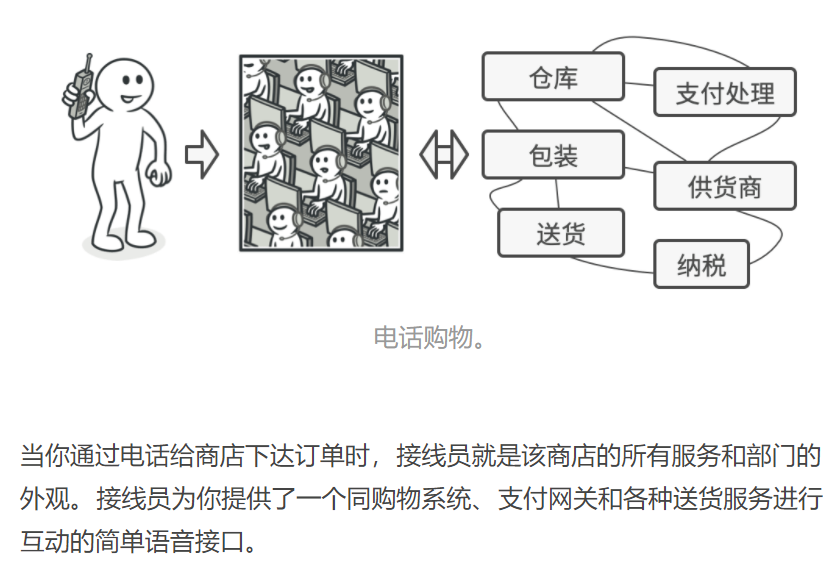
外观类为包含许多活动部件的复杂子系统提供一个简单的接口。 与直接调用子系统相比, 外观提供的功能可能比较有限, 但它却包含了客户端真正关心的功能。
如果你的程序需要与包含几十种功能的复杂库整合, 但只需使用其中非常少的功能, 那么使用外观模式会非常方便,
享元模式
在享元模式中可以共享的相同内容称为内部状态(IntrinsicState),而那些需要外部环境来设置的不能共享的内容称为外部状态(Extrinsic State),由于区分了内部状态和外部状态,因此可以通过设置不同的外部状态使得相同的对象可以具有一些不同的特征,而相同的内部状态是可以共享的。
在享元模式中通常会出现工厂模式,需要创建一个享元工厂来负责维护一个享元池(Flyweight Pool)用于存储具有相同内部状态的享元对象。
在享元模式中共享的是享元对象的内部状态,外部状态需要通过环境来设置。在实际使用中,能够共享的内部状态是有限的,因此享元对象一般都设计为较小的对象,它所包含的内部状态较少,这种对象也称为细粒度对象。享元模式的目的就是使用共享技术来实现大量细粒度对象的复用。
对象的常量数据通常被称为内在状态, 其位于对象中, 其他对象只能读取但不能修改其数值。 而对象的其他状态常常能被其他对象 “从外部” 改变, 因此被称为外在状态。
享元模式建议不在对象中存储外在状态, 而是将其传递给依赖于它的一个特殊方法(将一个仅存储内在状态的对象称为享元)。 程序只在对象中保存内在状态, 以方便在不同情景下重用。 这些对象的区别仅在于其内在状态 (与外在状态相比, 内在状态的变体要少很多), 因此你所需的对象数量会大大削减。
代理模式
示例1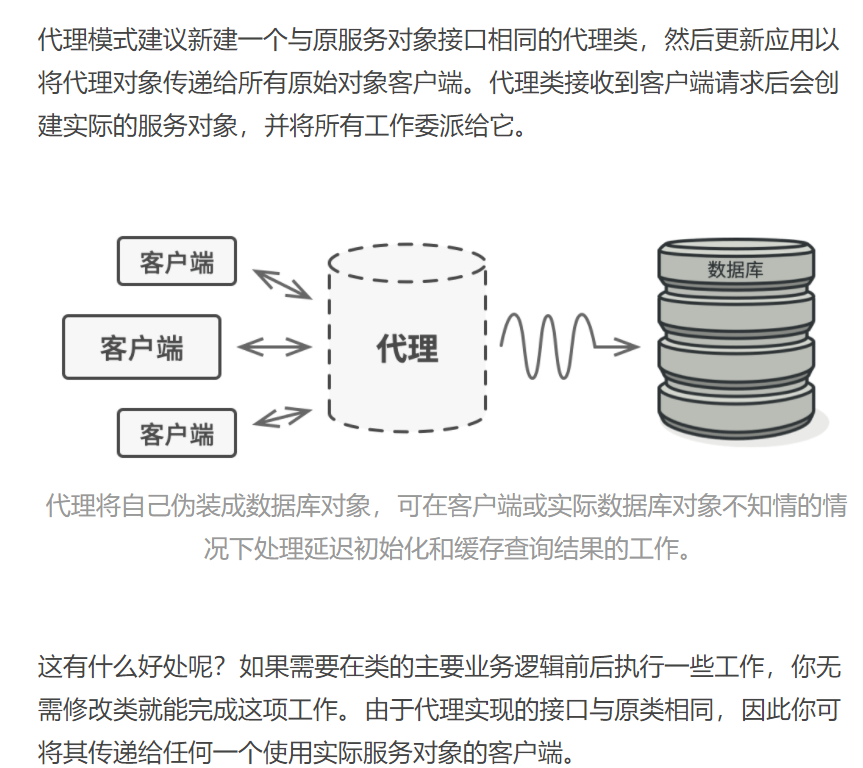
示例2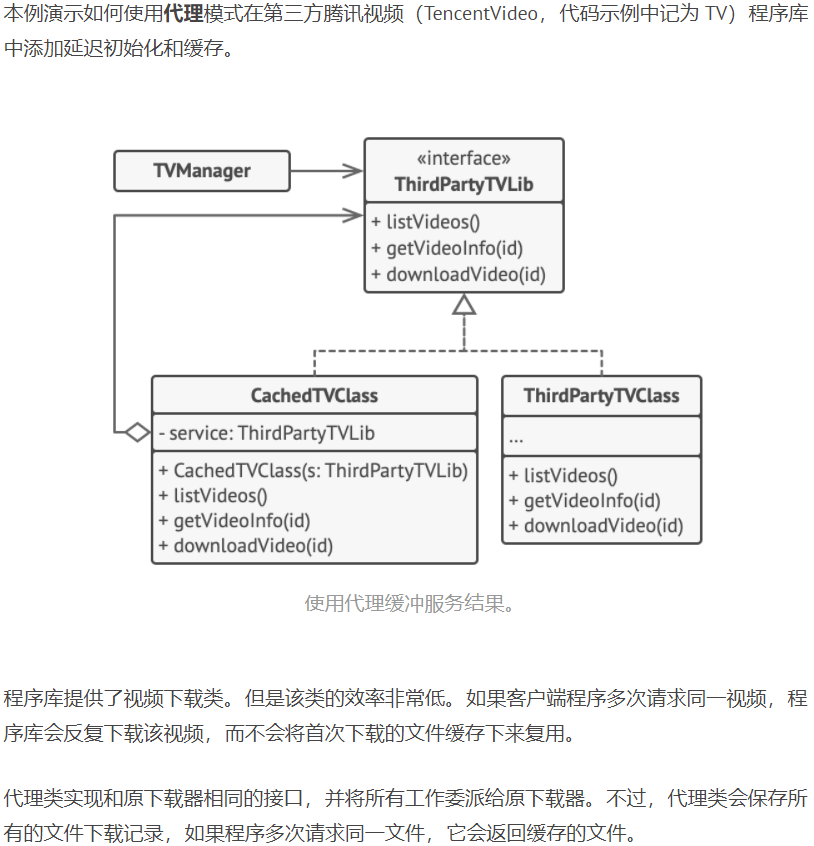
行为模式
行为模式负责对象间的高效沟通和职责委派。
责任链模式
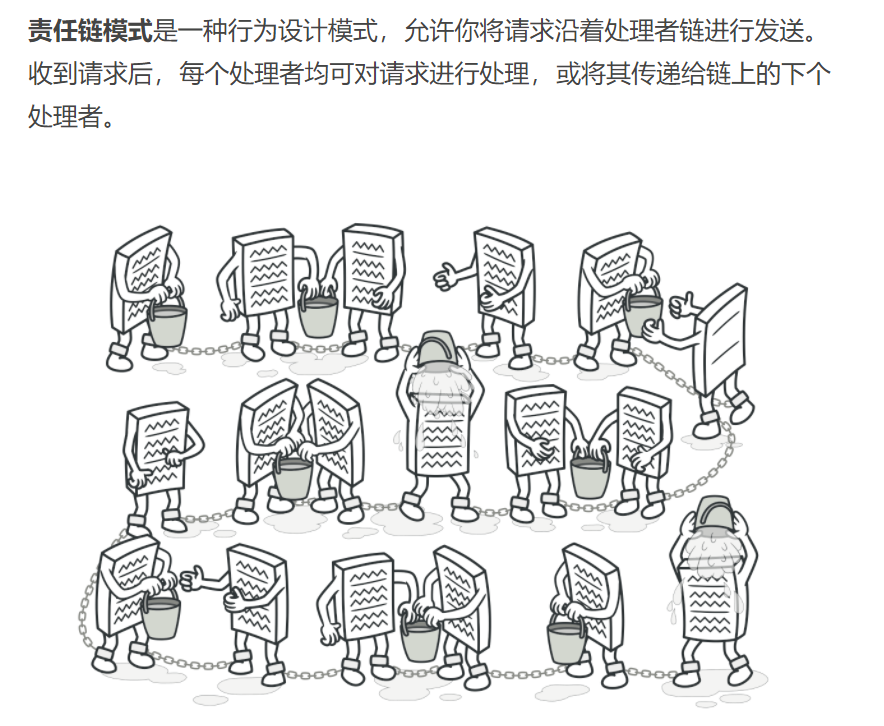
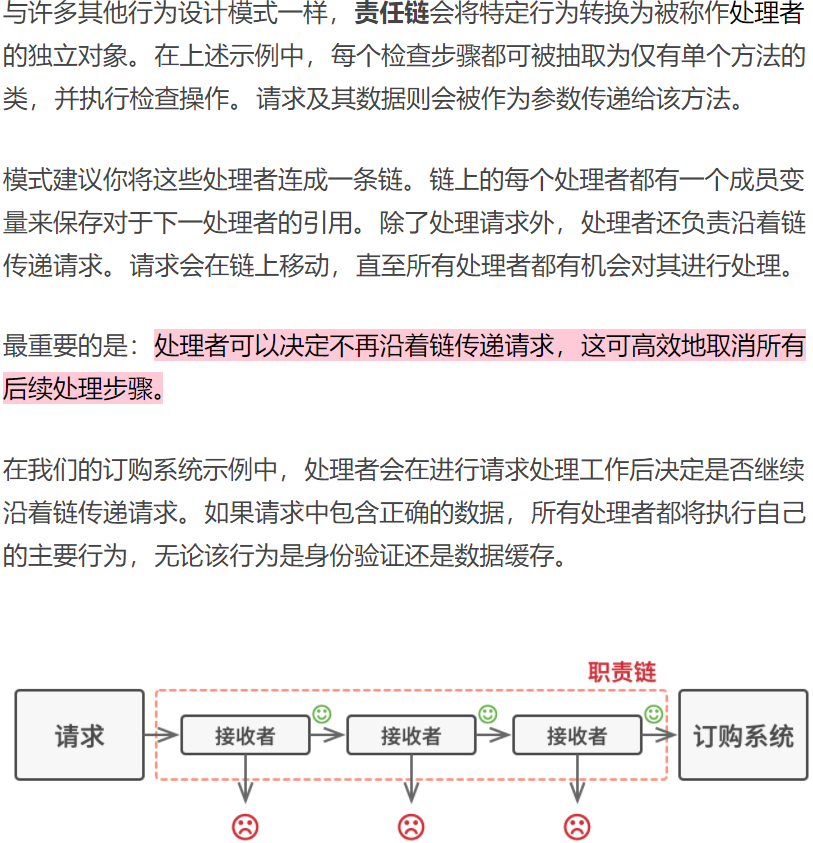

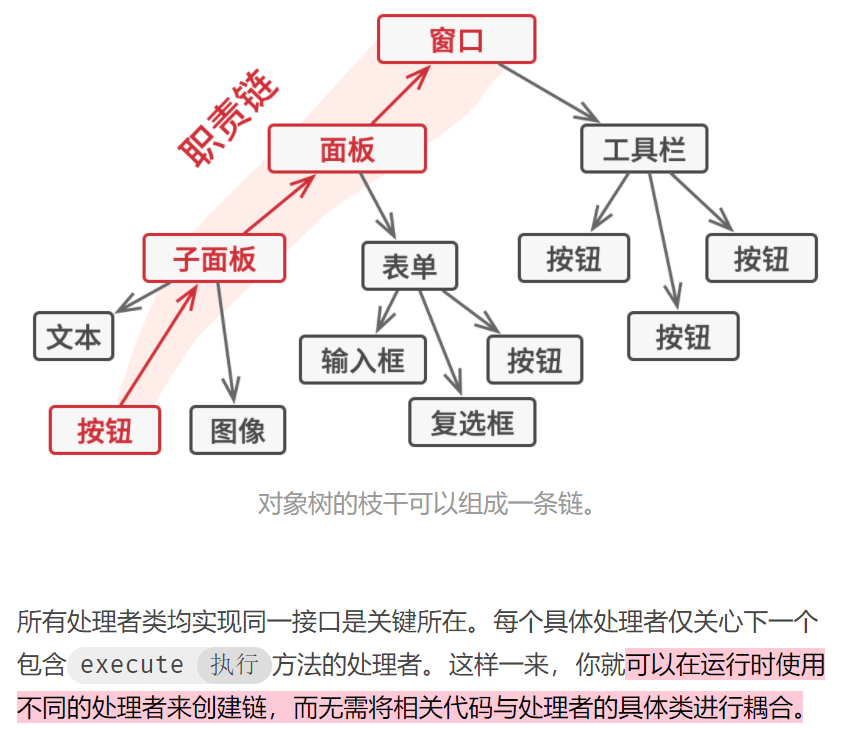
命令设计模式
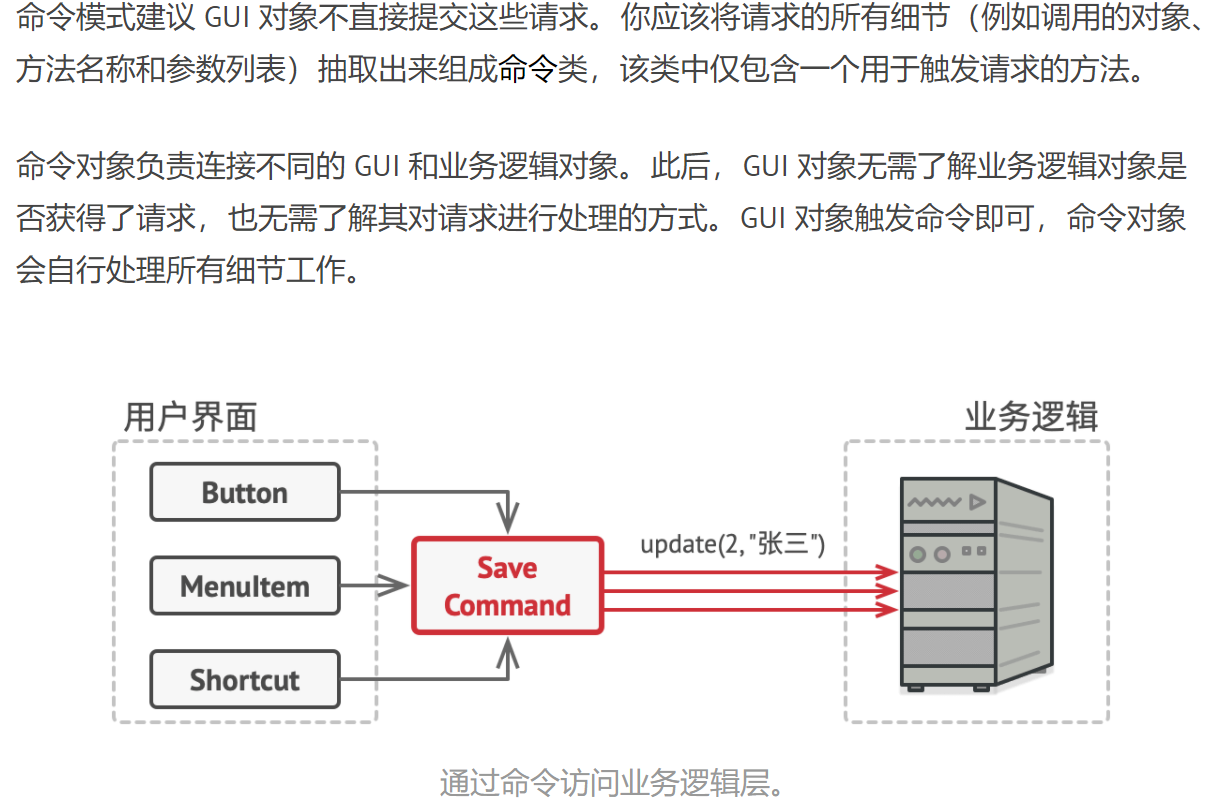


- 模式动机
在软件设计中,我们经常需要向某些对象发送请求,但是并不知道请求的接收者是谁,也不知道被请求的操作是哪个,我们只需在程序运行时指定具体的请求接收者即可,此时,可以使用命令模式来进行设计,使得请求发送者与请求接收者消除彼此之间的耦合,让对象之间的调用关系更加灵活。
命令模式可以对发送者和接收者完全解耦 (比如点餐者和厨师),发送者与接收者之间没有直接引用关系,发送请求的对象只需要知道如何发送请求,而不必知道如何完成请求。这就是命令模式的模式动机。
- 模式定义
命令模式(Command Pattern):将一个请求封装为一个对象,从而使我们可用不同的请求对客户进行参数化(比如不同的顾客有不同的点餐单);对请求排队或者记录请求日志,以及支持可撤销的操作。命令模式是一种对象行为型模式,其别名为动作(Action)模式或事务(Transaction)模式。
中介者设计模式
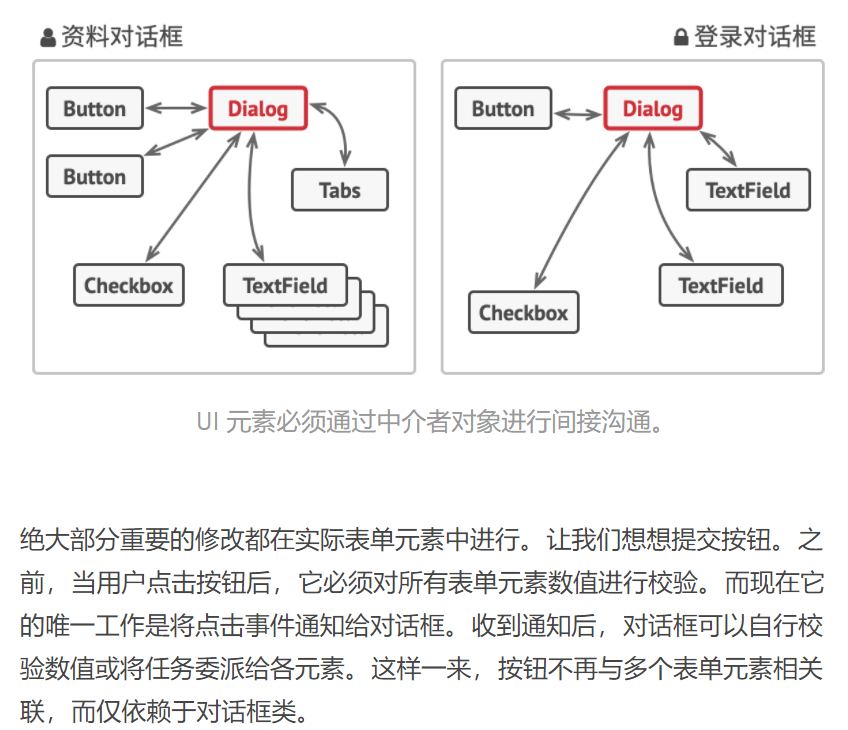

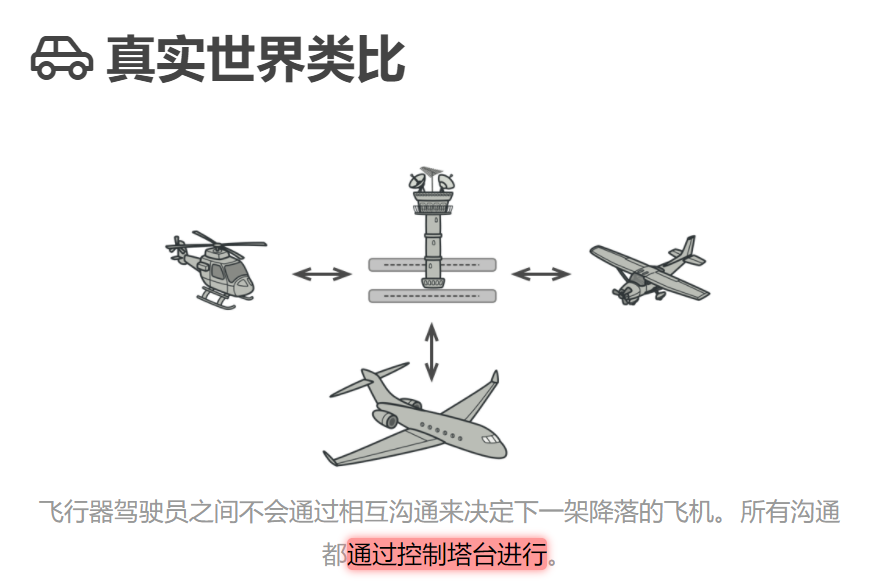
对于一个模块,可能由很多对象构成,而且这些对象之间可能存在相互的引用,为了减少对象两两之间复杂的引用关系,使之成为一个松耦合的系统,我们需要使用中介者模式,这就是中介者模式的模式动机。
中介者模式(Mediator Pattern)定义:用一个中介对象来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散,而且可以独立地改变它们之间的交互。中介者模式又称为调停者模式,它是一种对象行为型模式。
中介者模式可以使对象之间的关系数量急剧减少。中介者承担两方面的职责:
- 中转作用(结构性):通过中介者提供的中转作用,各个同事对象就不再需要显式引用其他同事,当需要和其他同事进行通信时,通过中介者即可。该中转作用属于中介者在结构上的支持。
- 协调作用(行为性):中介者可以更进一步的对同事之间的关系进行封装,同事可以一致地和中介者进行交互,而不需要指明中介者需要具体怎么做,中介者根据封装在自身内部的协调逻辑,对同事的请求进行进一步处理,将同事成员之间的关系行为进行分离和封装。该协调作用属于中介者在行为上的支持。
观察者模式
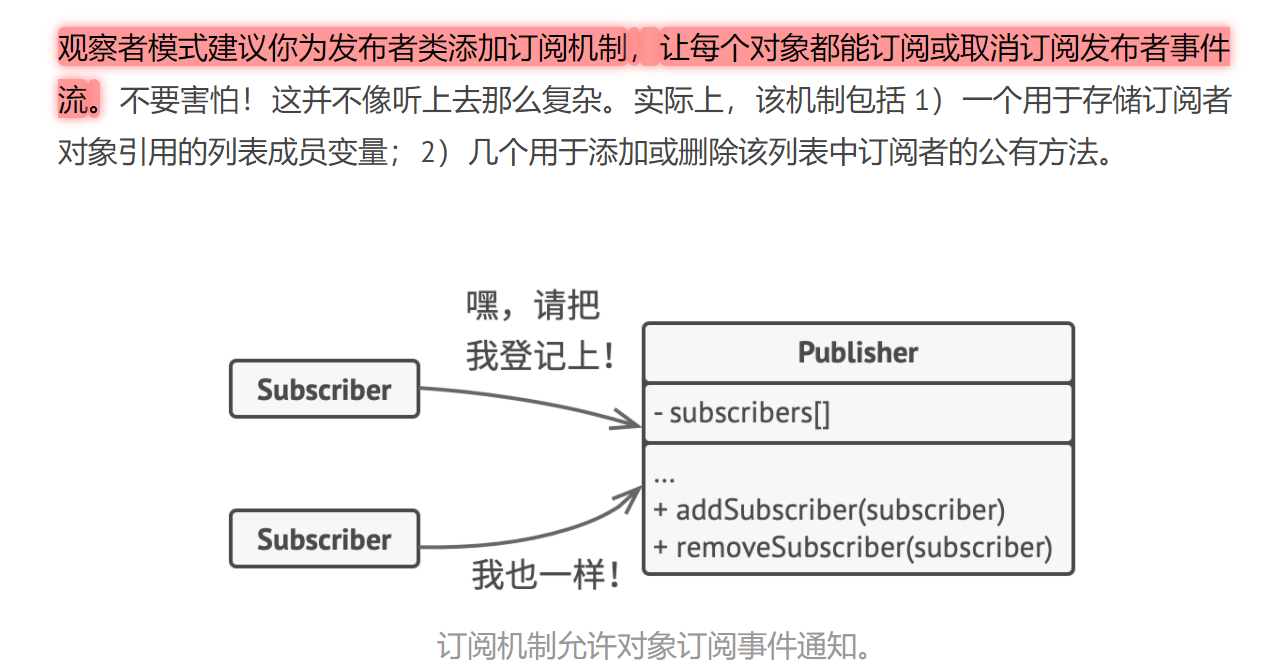

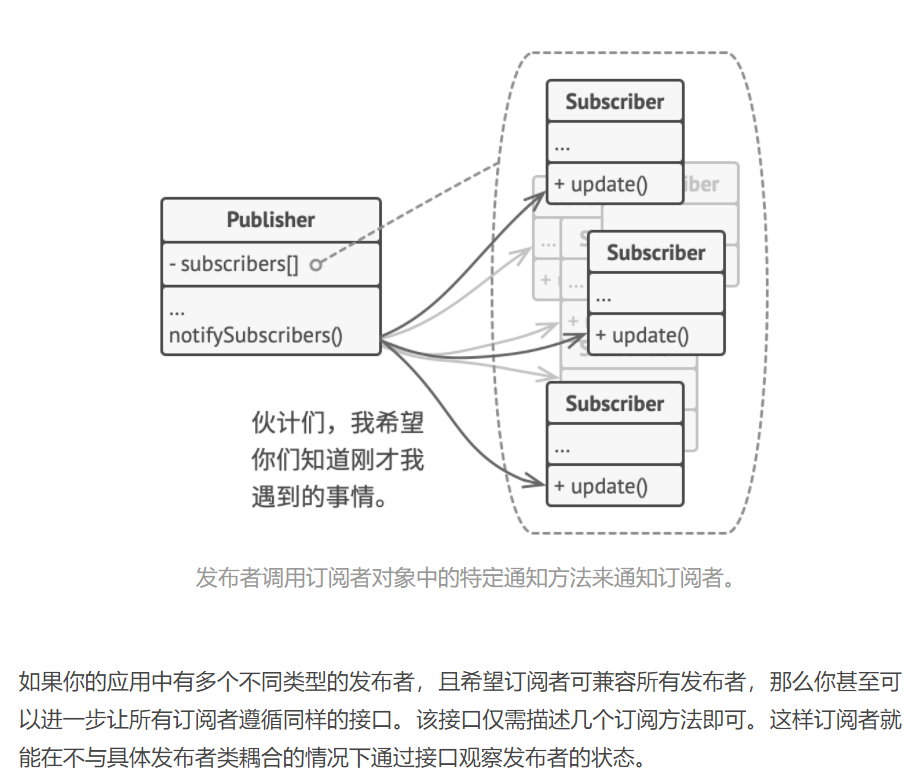
模式动机
建立一种对象与对象之间的依赖关系,一个对象发生改变时将自动通知其他对象,其他对象将相应做出反应。在此,发生改变的对象称为观察目标,而被通知的对象称为观察者,一个观察目标可以对应多个观察者,而且这些观察者之间没有相互联系,可以根据需要增加和删除观察者,使得系统更易于扩展,这就是观察者模式的模式动机。模式定义
观察者模式(Observer Pattern):定义对象间的一种一对多依赖关系,使得每当一个对象状态发生改变时,其相关依赖对象皆得到通知并被自动更新。观察者模式又叫做发布-订阅(Publish/Subscribe)模式、模型-视图(Model/View)模式、源-监听器(Source/Listener)模式或从属者(Dependents)模式。
状态模式
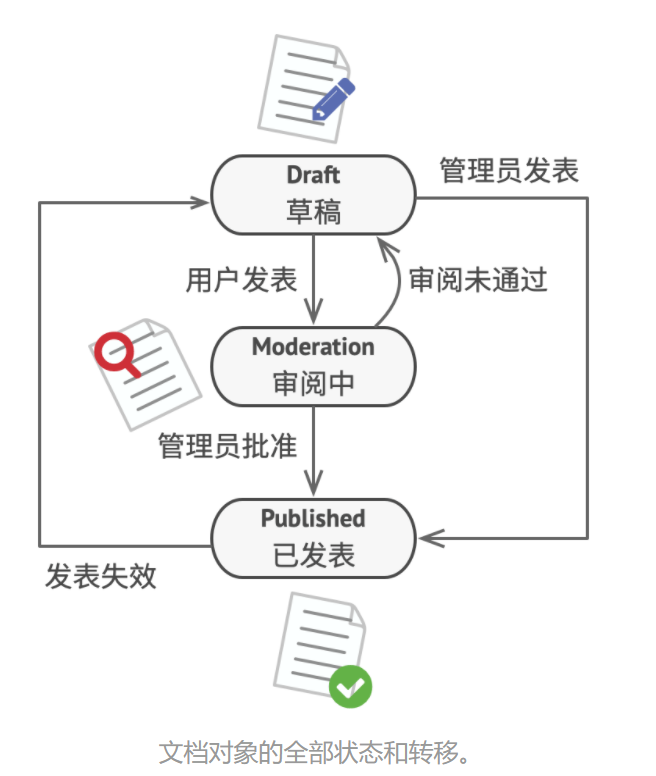
其主要思想是程序在任意时刻仅可处于几种有限的状态中。 在任何一个特定状态中, 程序的行为都不相同, 且可瞬间从一个状态切换到另一个状态。 不过, 根据当前状态, 程序可能会切换到另外一种状态, 也可能会保持当前状态不变。 这些数量有限且预先定义的状态切换规则被称为转移。
你还可将该方法应用在对象上。 假如你有一个 文档Document类。 文档可能会处于 草稿Draft 、 审阅中Moderation和 已发布Published三种状态中的一种。 文档的 publish发布方法在不同状态下的行为略有不同:
- 处于 草稿状态时, 它会将文档转移到审阅中状态。
- 处于 审阅中状态时, 如果当前用户是管理员, 它会公开发布文档。
- 处于 已发布状态时, 它不会进行任何操作。
策略模式
策略模式是一种行为设计模式, 它能让你定义一系列算法, 并将每种算法分别放入独立的类中, 以使算法的对象能够相互替换。
策略模式建议找出负责用许多不同方式完成特定任务的类, 然后将其中的算法抽取到一组被称为策略的独立类中。

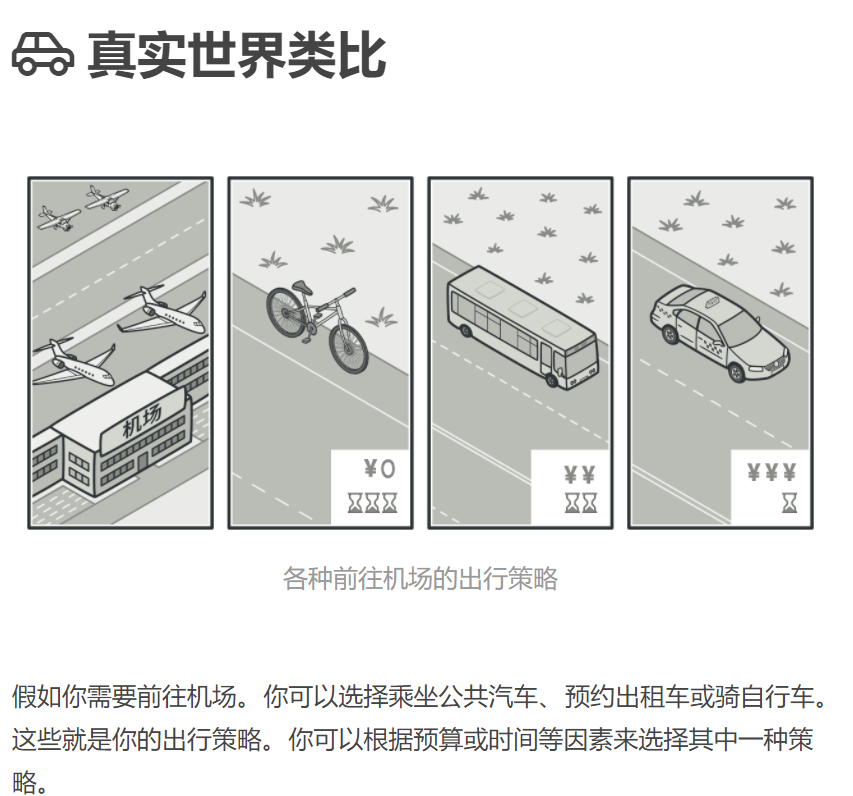
模式动机
- 完成一项任务,往往可以有多种不同的方式,每一种方式称为一个策略,我们可以根据环境或者条件的不同选择不同的策略来完成该项任务。
- 在软件开发中也常常遇到类似的情况,实现某一个功能有多个途径,此时可以使用一种设计模式来使得系统可以灵活地选择解决途径,也能够方便地增加新的解决途径。
- 在软件系统中,有许多算法可以实现某一功能,如查找、排序等,一种常用的方法是硬编码(Hard Coding)在一个类中,如需要提供多种查找算法,可以将这些算法写到一个类中,在该类中提供多个方法,每一个方法对应一个具体的查找算法;当然也可以将这些查找算法封装在一个统一的方法中,通过if…else…等条件判断语句来进行选择。这两种实现方法我们都可以称之为硬编码,如果需要增加一种新的查找算法,需要修改封装算法类的源代码;更换查找算法,也需要修改客户端调用代码。在这个算法类中封装了大量查找算法,该类代码将较复杂,维护较为困难。
- 除了提供专门的查找算法类之外,还可以在客户端程序中直接包含算法代码,这种做法更不可取,将导致客户端程序庞大而且难以维护,如果存在大量可供选择的算法时问题将变得更加严重。
- 为了解决这些问题,可以定义一些独立的类来封装不同的算法,每一个类封装一个具体的算法,在这里,每一个封装算法的类我们都可以称之为策略(Strategy),为了保证这些策略的一致性,一般会用一个抽象的策略类来做算法的定义,而具体每种算法则对应于一个具体策略类。
模式定义
策略模式(Strategy Pattern):定义一系列算法,将每一个算法封装起来,并让它们可以相互替换。策略模式让算法独立于使用它的客户而变化,也称为政策模式(Policy)。
模板方法模式
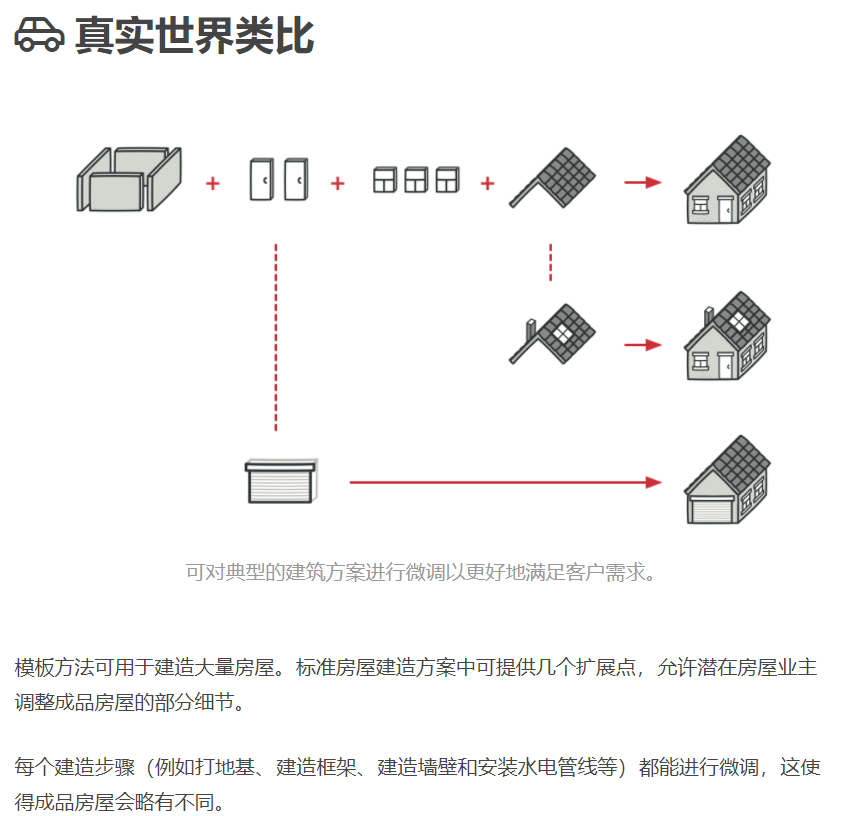

还有另一种名为钩子的步骤。 钩子是内容为空的可选步骤。 即使不重写钩子, 模板方法也能工作。 钩子通常放置在算法重要步骤的前后, 为子类提供额外的算法扩展点。
访问者模式
访问者模式建议将新行为放入一个名为访问者的独立类中, 而不是试图将其整合到已有类中。 现在, 需要执行操作的原始对象将作为参数被传递给访问者中的方法, 让方法能访问对象所包含的一切必要数据。